MLLM-Bench, Evaluating Multi-modal LLMs using GPT-4V
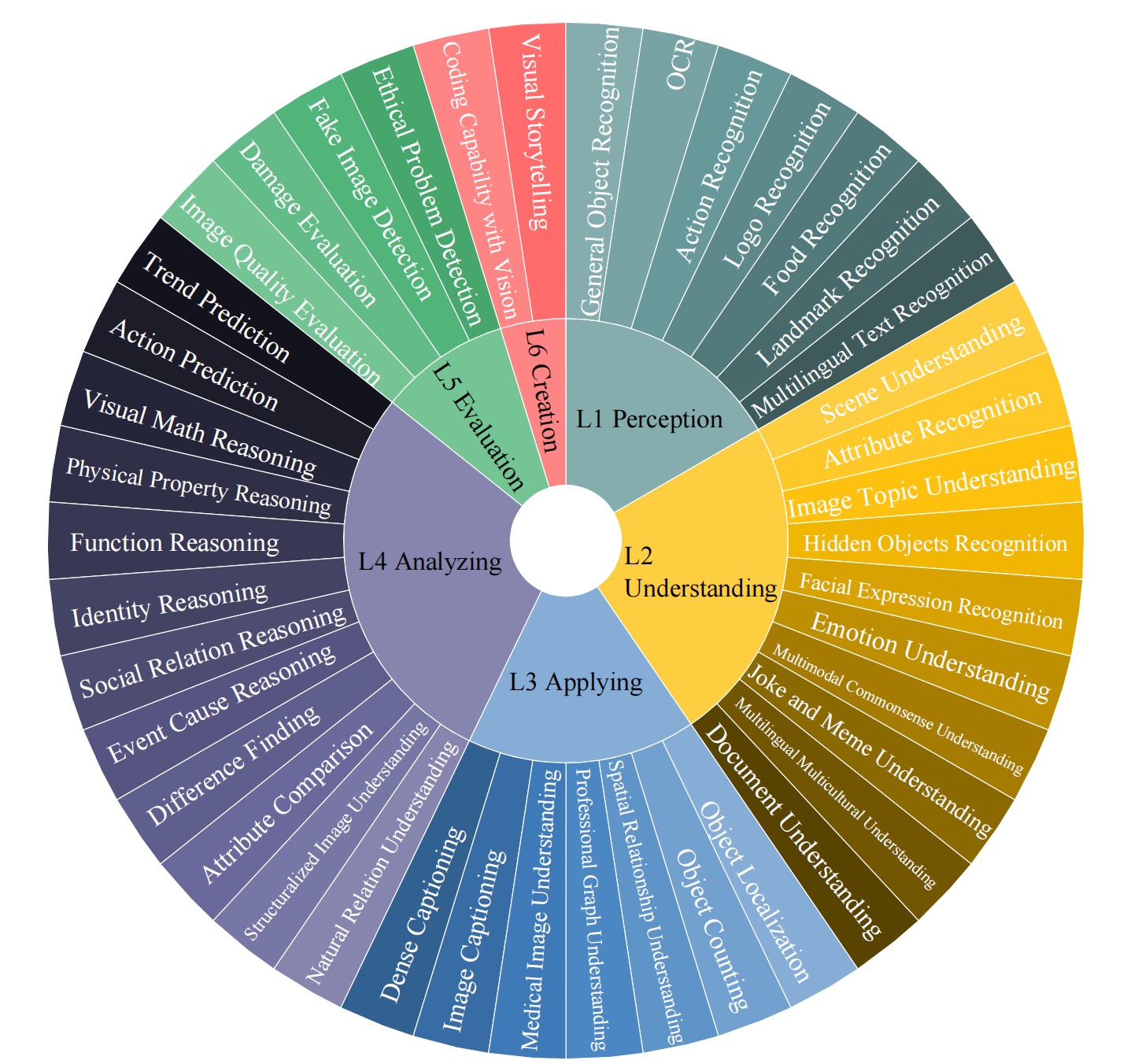
In the pursuit of Artificial General Intelligence (AGI), the integration of vision in language models has marked a significant milestone. The advent of vision-language models (MLLMs) like GPT-4V have expanded AI applications, aligning with the multi-modal capabilities of the human brain. However, evaluating the efficacy of MLLMs poses a substantial challenge due to the subjective nature of tasks that lack definitive answers. Existing automatic evaluation methodologies on multi-modal large language models rely on objective queries that have standard answers, inadequately addressing the nuances of creative and associative multi-modal tasks. To address this, we introduce MLLM-Bench, an innovative benchmark inspired by Vicuna, spanning a diverse array of scenarios, including Perception, Understanding, Applying, Analyzing, Evaluating, and Creation along with the ethical consideration. MLLM-Bench is designed to reflect user experience more accurately and provide a more holistic assessment of model performance. Comparative evaluations indicate a significant performance gap between existing open-source models and GPT-4V. We posit that MLLM-Bench will catalyze progress in the open-source community towards developing user-centric vision-language models that meet a broad spectrum of real-world applications. See online leaderboard in \url{https://mllm-bench.llmzoo.com}.
PDF Abstract
 SEED-Bench
SEED-Bench
