MoPro: Webly Supervised Learning with Momentum Prototypes
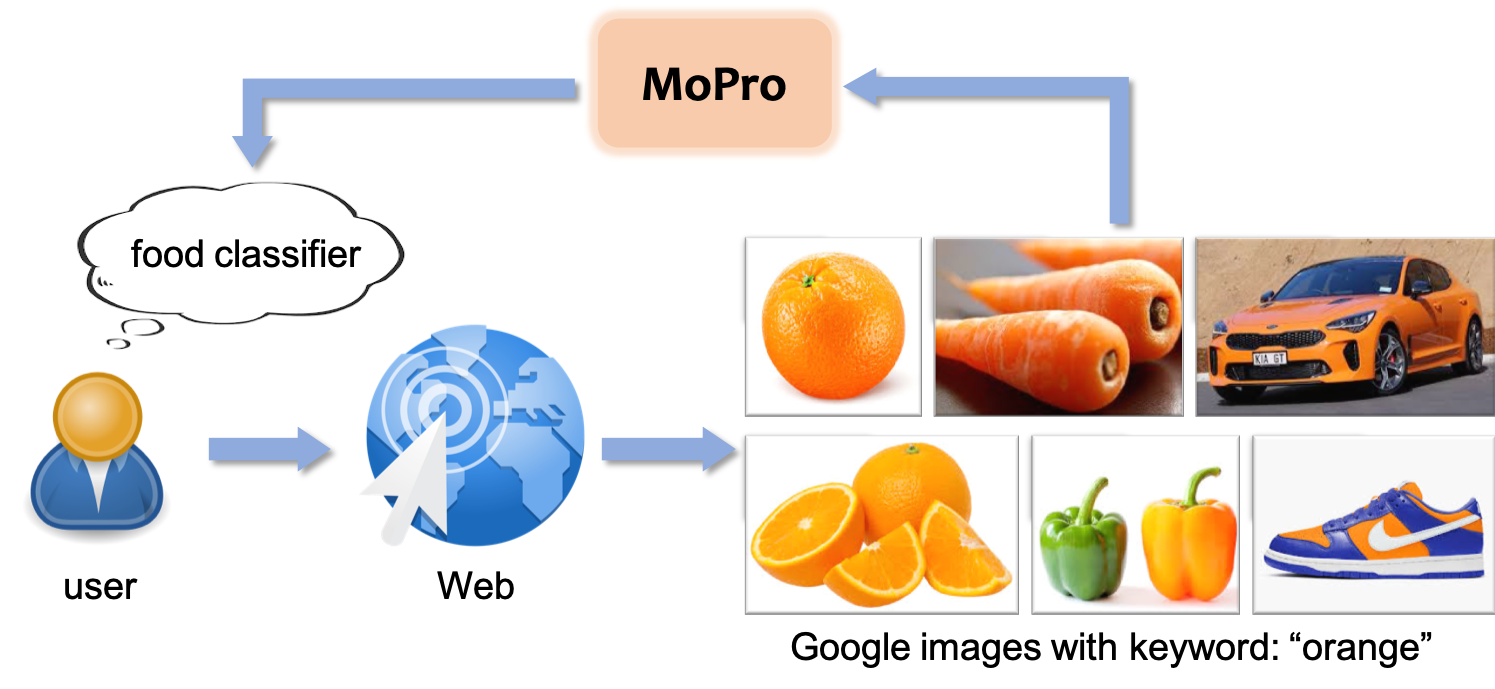
We propose a webly-supervised representation learning method that does not suffer from the annotation unscalability of supervised learning, nor the computation unscalability of self-supervised learning. Most existing works on webly-supervised representation learning adopt a vanilla supervised learning method without accounting for the prevalent noise in the training data, whereas most prior methods in learning with label noise are less effective for real-world large-scale noisy data. We propose momentum prototypes (MoPro), a simple contrastive learning method that achieves online label noise correction, out-of-distribution sample removal, and representation learning. MoPro achieves state-of-the-art performance on WebVision, a weakly-labeled noisy dataset. MoPro also shows superior performance when the pretrained model is transferred to down-stream image classification and detection tasks. It outperforms the ImageNet supervised pretrained model by +10.5 on 1-shot classification on VOC, and outperforms the best self-supervised pretrained model by +17.3 when finetuned on 1\% of ImageNet labeled samples. Furthermore, MoPro is more robust to distribution shifts. Code and pretrained models are available at https://github.com/salesforce/MoPro.
PDF Abstract ICLR 2021 PDF ICLR 2021 AbstractCode





 ImageNet
ImageNet
 MS COCO
MS COCO
 Places205
Places205
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 WebVision
WebVision
 OmniBenchmark
OmniBenchmark
Results from the Paper
 Ranked #12 on
Image Classification
on OmniBenchmark
(using extra training data)
Ranked #12 on
Image Classification
on OmniBenchmark
(using extra training data)
