Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
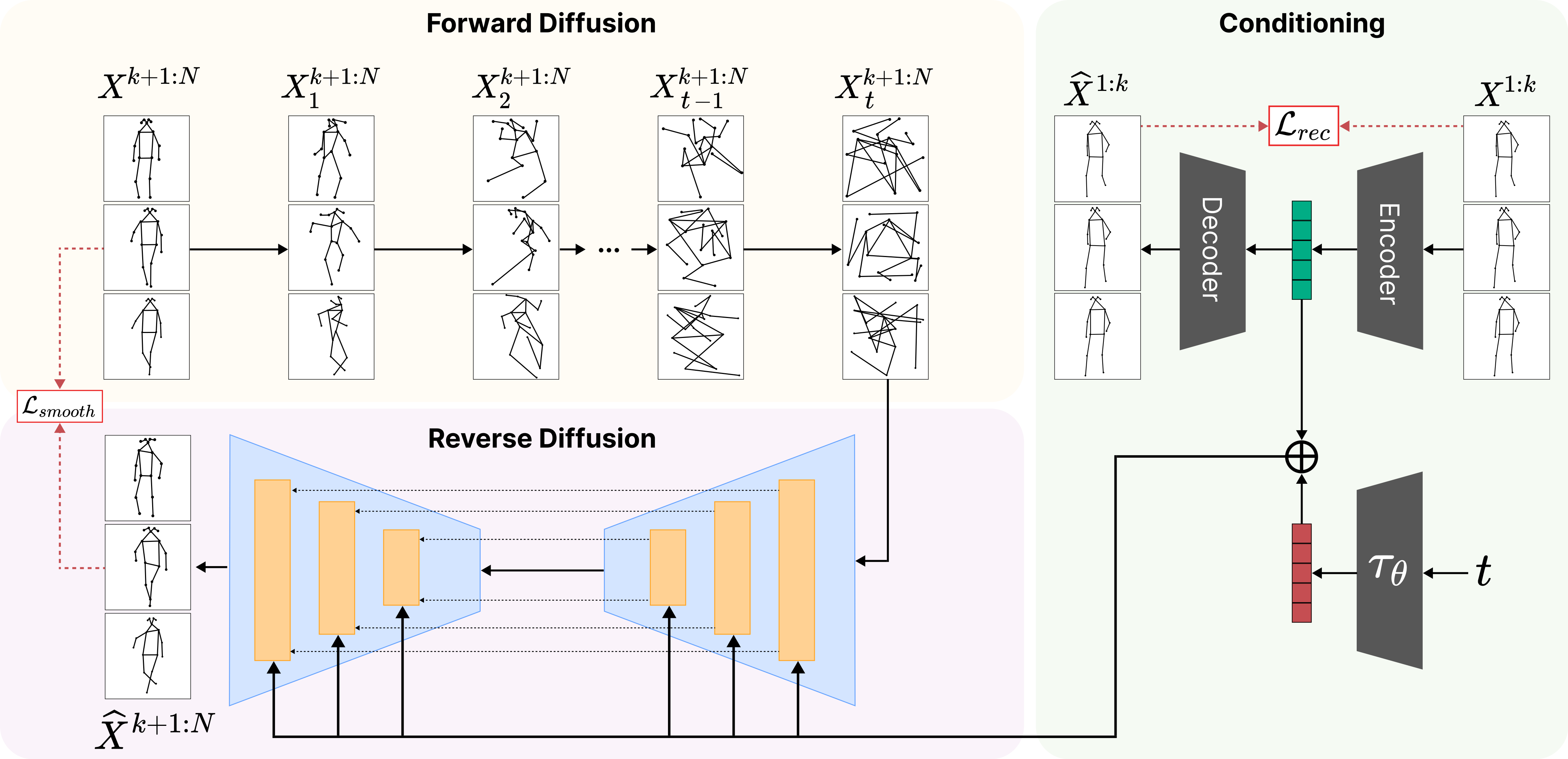
Anomalies are rare and anomaly detection is often therefore framed as One-Class Classification (OCC), i.e. trained solely on normalcy. Leading OCC techniques constrain the latent representations of normal motions to limited volumes and detect as abnormal anything outside, which accounts satisfactorily for the openset'ness of anomalies. But normalcy shares the same openset'ness property since humans can perform the same action in several ways, which the leading techniques neglect. We propose a novel generative model for video anomaly detection (VAD), which assumes that both normality and abnormality are multimodal. We consider skeletal representations and leverage state-of-the-art diffusion probabilistic models to generate multimodal future human poses. We contribute a novel conditioning on the past motion of people and exploit the improved mode coverage capabilities of diffusion processes to generate different-but-plausible future motions. Upon the statistical aggregation of future modes, an anomaly is detected when the generated set of motions is not pertinent to the actual future. We validate our model on 4 established benchmarks: UBnormal, HR-UBnormal, HR-STC, and HR-Avenue, with extensive experiments surpassing state-of-the-art results.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract



 ShanghaiTech Campus
ShanghaiTech Campus
 UBnormal
UBnormal

