Post-Training Piecewise Linear Quantization for Deep Neural Networks
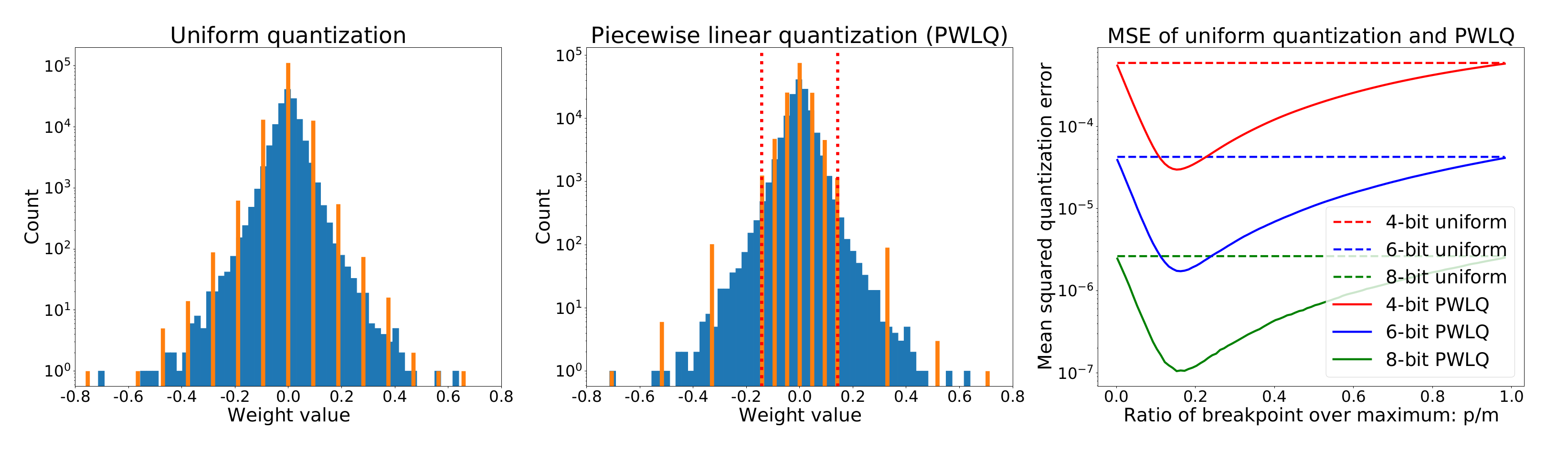
Quantization plays an important role in the energy-efficient deployment of deep neural networks on resource-limited devices. Post-training quantization is highly desirable since it does not require retraining or access to the full training dataset. The well-established uniform scheme for post-training quantization achieves satisfactory results by converting neural networks from full-precision to 8-bit fixed-point integers. However, it suffers from significant performance degradation when quantizing to lower bit-widths. In this paper, we propose a piecewise linear quantization (PWLQ) scheme to enable accurate approximation for tensor values that have bell-shaped distributions with long tails. Our approach breaks the entire quantization range into non-overlapping regions for each tensor, with each region being assigned an equal number of quantization levels. Optimal breakpoints that divide the entire range are found by minimizing the quantization error. Compared to state-of-the-art post-training quantization methods, experimental results show that our proposed method achieves superior performance on image classification, semantic segmentation, and object detection with minor overhead.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




