Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey
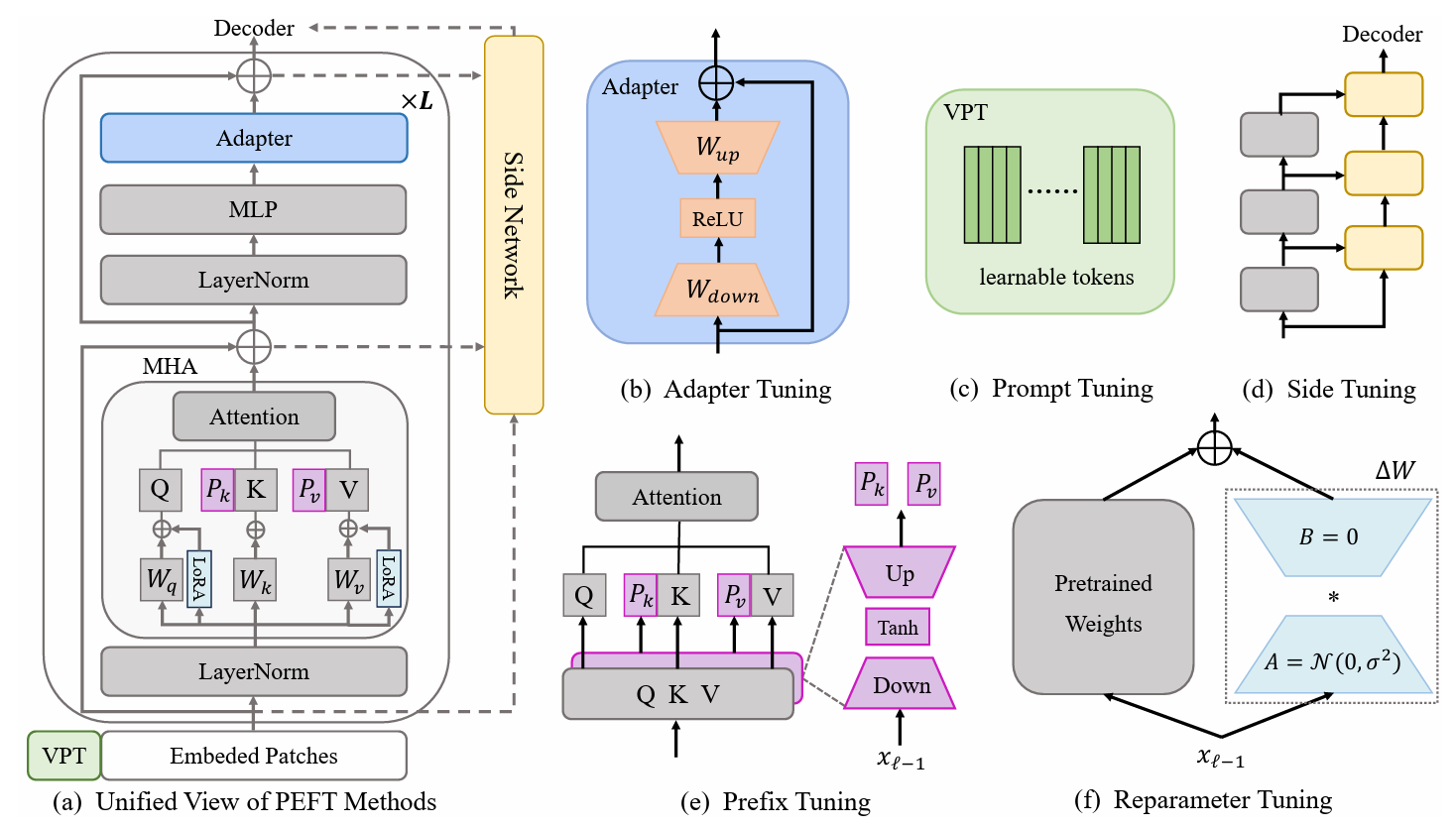
Large-scale pre-trained vision models (PVMs) have shown great potential for adaptability across various downstream vision tasks. However, with state-of-the-art PVMs growing to billions or even trillions of parameters, the standard full fine-tuning paradigm is becoming unsustainable due to high computational and storage demands. In response, researchers are exploring parameter-efficient fine-tuning (PEFT), which seeks to exceed the performance of full fine-tuning with minimal parameter modifications. This survey provides a comprehensive overview and future directions for visual PEFT, offering a systematic review of the latest advancements. First, we provide a formal definition of PEFT and discuss model pre-training methods. We then categorize existing methods into three categories: addition-based, partial-based, and unified-based. Finally, we introduce the commonly used datasets and applications and suggest potential future research challenges. A comprehensive collection of resources is available at https://github.com/synbol/Awesome-Parameter-Efficient-Transfer-Learning.
PDF Abstract

 MS COCO
MS COCO
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
