PillarGrid: Deep Learning-based Cooperative Perception for 3D Object Detection from Onboard-Roadside LiDAR
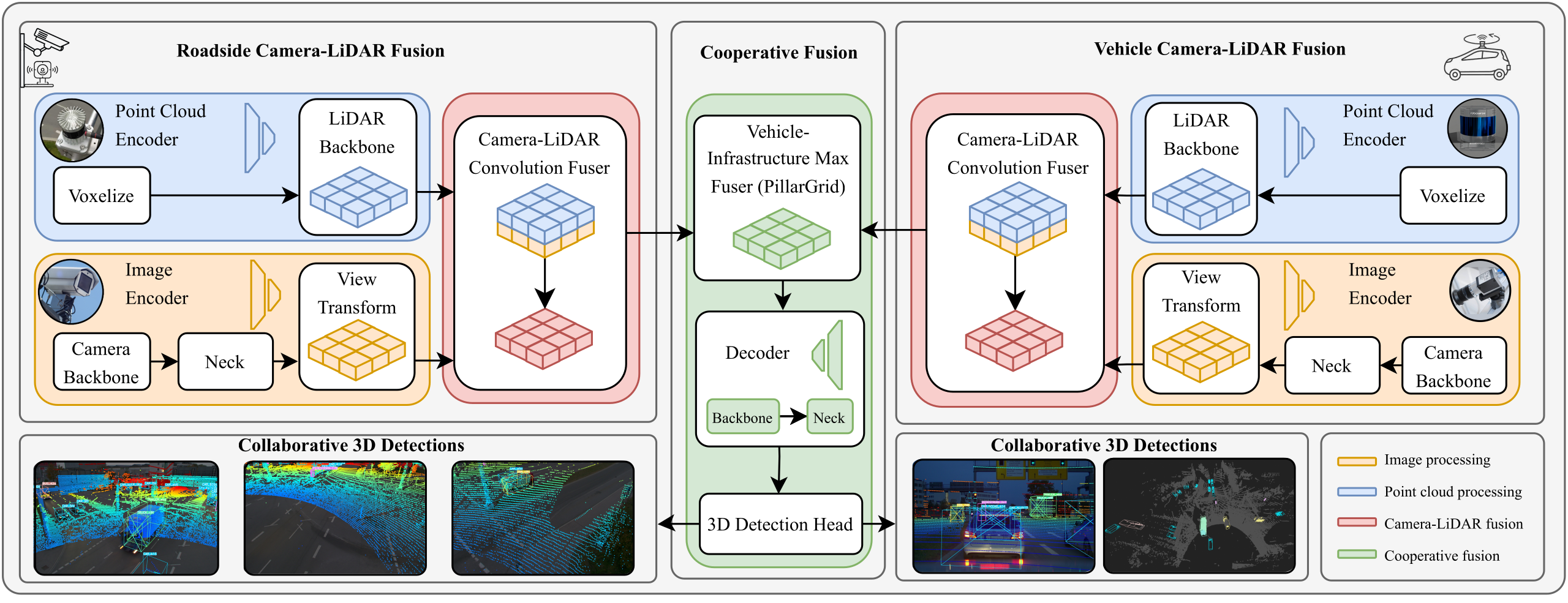
3D object detection plays a fundamental role in enabling autonomous driving, which is regarded as the significant key to unlocking the bottleneck of contemporary transportation systems from the perspectives of safety, mobility, and sustainability. Most of the state-of-the-art (SOTA) object detection methods from point clouds are developed based on a single onboard LiDAR, whose performance will be inevitably limited by the range and occlusion, especially in dense traffic scenarios. In this paper, we propose \textit{PillarGrid}, a novel cooperative perception method fusing information from multiple 3D LiDARs (both on-board and roadside), to enhance the situation awareness for connected and automated vehicles (CAVs). PillarGrid consists of four main phases: 1) cooperative preprocessing of point clouds, 2) pillar-wise voxelization and feature extraction, 3) grid-wise deep fusion of features from multiple sensors, and 4) convolutional neural network (CNN)-based augmented 3D object detection. A novel cooperative perception platform is developed for model training and testing. Extensive experimentation shows that PillarGrid outperforms the SOTA single-LiDAR-based 3D object detection methods with respect to both accuracy and range by a large margin.
PDF Abstract




 KITTI
KITTI
 CARLA
CARLA
