Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
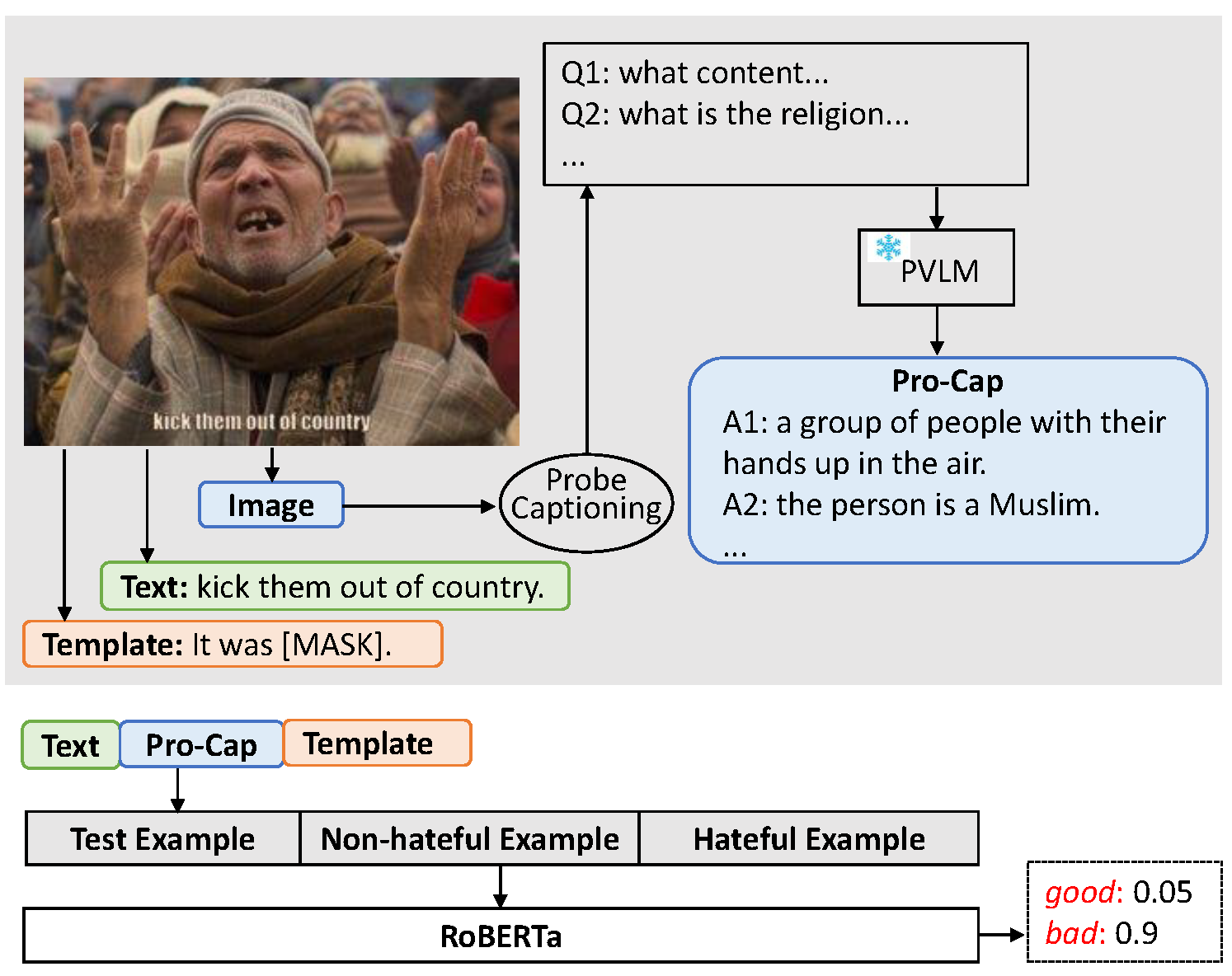
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
PDF Abstract





 MS COCO
MS COCO
 Hateful Memes
Hateful Memes
