Prompt Vision Transformer for Domain Generalization
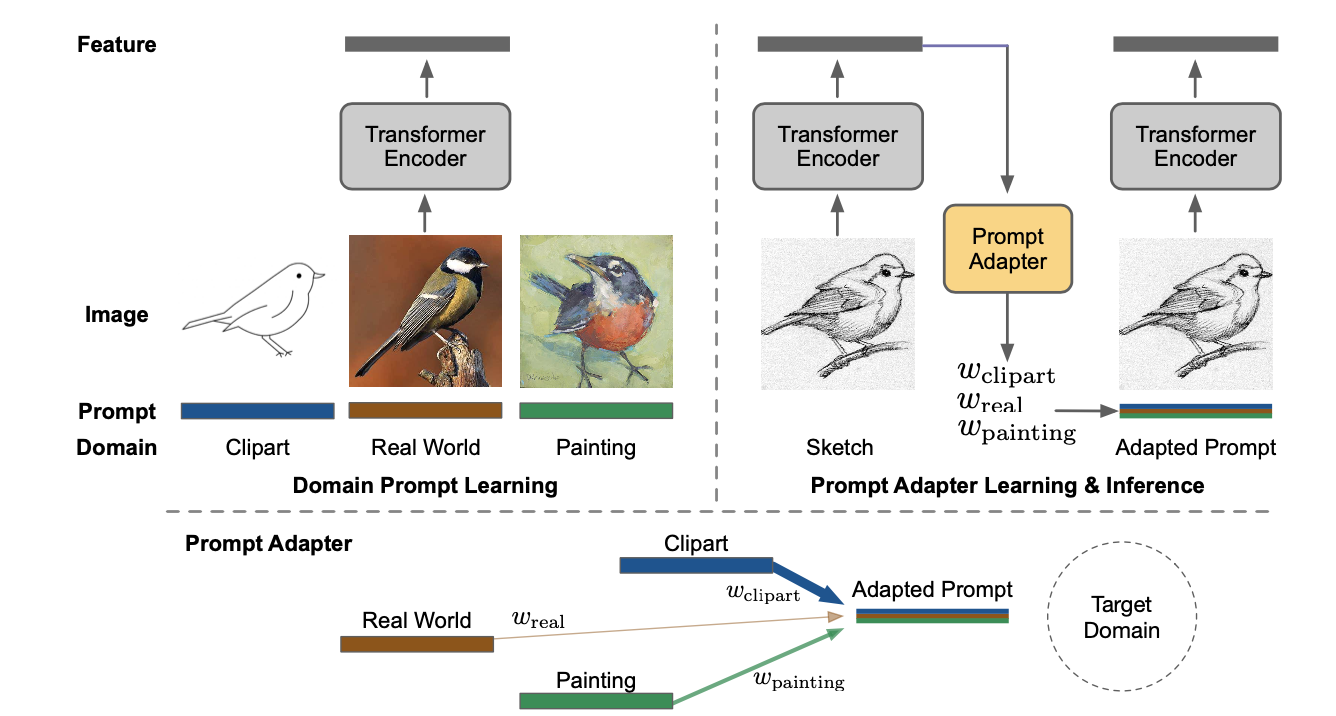
Though vision transformers (ViTs) have exhibited impressive ability for representation learning, we empirically find that they cannot generalize well to unseen domains with previous domain generalization algorithms. In this paper, we propose a novel approach DoPrompt based on prompt learning to embed the knowledge of source domains in domain prompts for target domain prediction. Specifically, domain prompts are prepended before ViT input tokens from the corresponding source domain. Each domain prompt learns domain-specific knowledge efficiently since it is optimized only for one domain. Meanwhile, we train a prompt adapter to produce a suitable prompt for each input image based on the learned source domain prompts. At test time, the adapted prompt generated by the prompt adapter can exploit the similarity between the feature of the out-of-domain image and source domains to properly integrate the source domain knowledge. Extensive experiments are conducted on four benchmark datasets. Our approach achieves 1.4% improvements in the averaged accuracy, which is 3.5 times the improvement of the state-of-the-art algorithm with a ViT backbone.
PDF Abstract


 ImageNet
ImageNet
 Office-Home
Office-Home
 PACS
PACS
