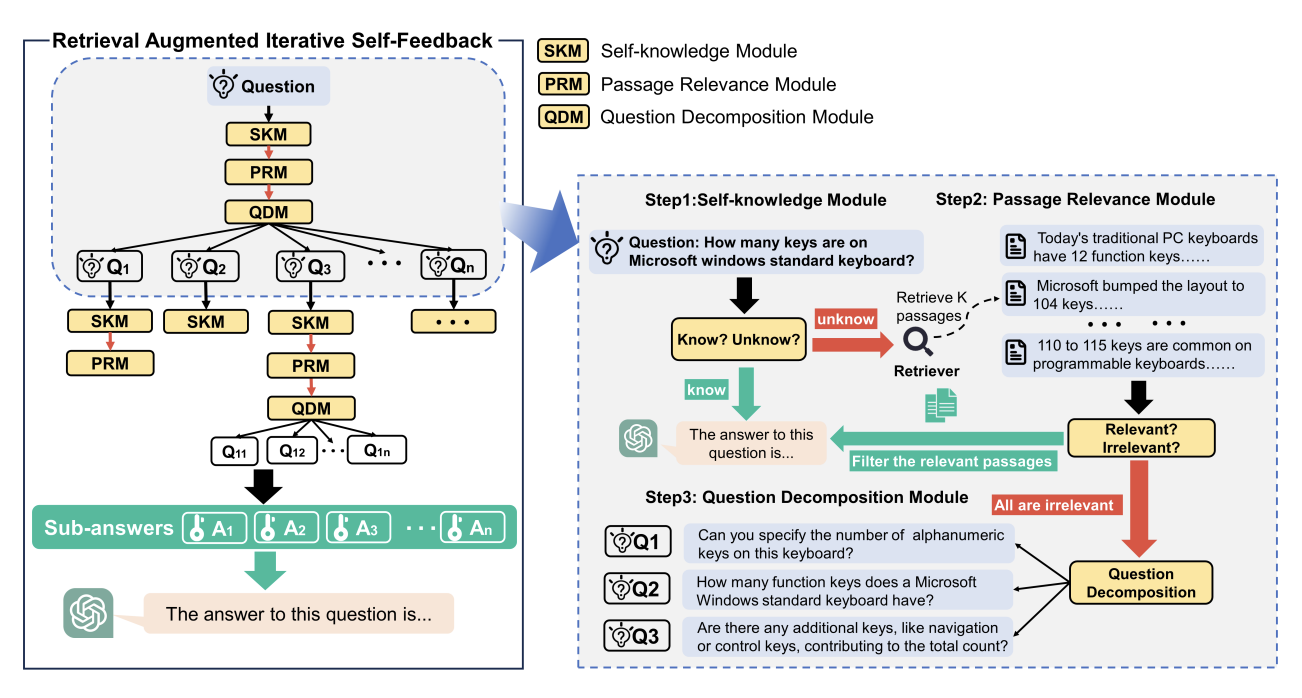
RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
Large language models (LLMs) demonstrate exceptional performance in numerous tasks but still heavily rely on knowledge stored in their parameters. Moreover, updating this knowledge incurs high training costs. Retrieval-augmented generation (RAG) methods address this issue by integrating external knowledge. The model can answer questions it couldn't previously by retrieving knowledge relevant to the query. This approach improves performance in certain scenarios for specific tasks. However, if irrelevant texts are retrieved, it may impair model performance. In this paper, we propose Retrieval Augmented Iterative Self-Feedback (RA-ISF), a framework that iteratively decomposes tasks and processes them in three submodules to enhance the model's problem-solving capabilities. Experiments show that our method outperforms existing benchmarks, performing well on models like GPT3.5, Llama2, significantly enhancing factual reasoning capabilities and reducing hallucinations.
PDF Abstract

 Natural Questions
Natural Questions
 TriviaQA
TriviaQA
 HotpotQA
HotpotQA
