Real-time Adversarial Perturbations against Deep Reinforcement Learning Policies: Attacks and Defenses
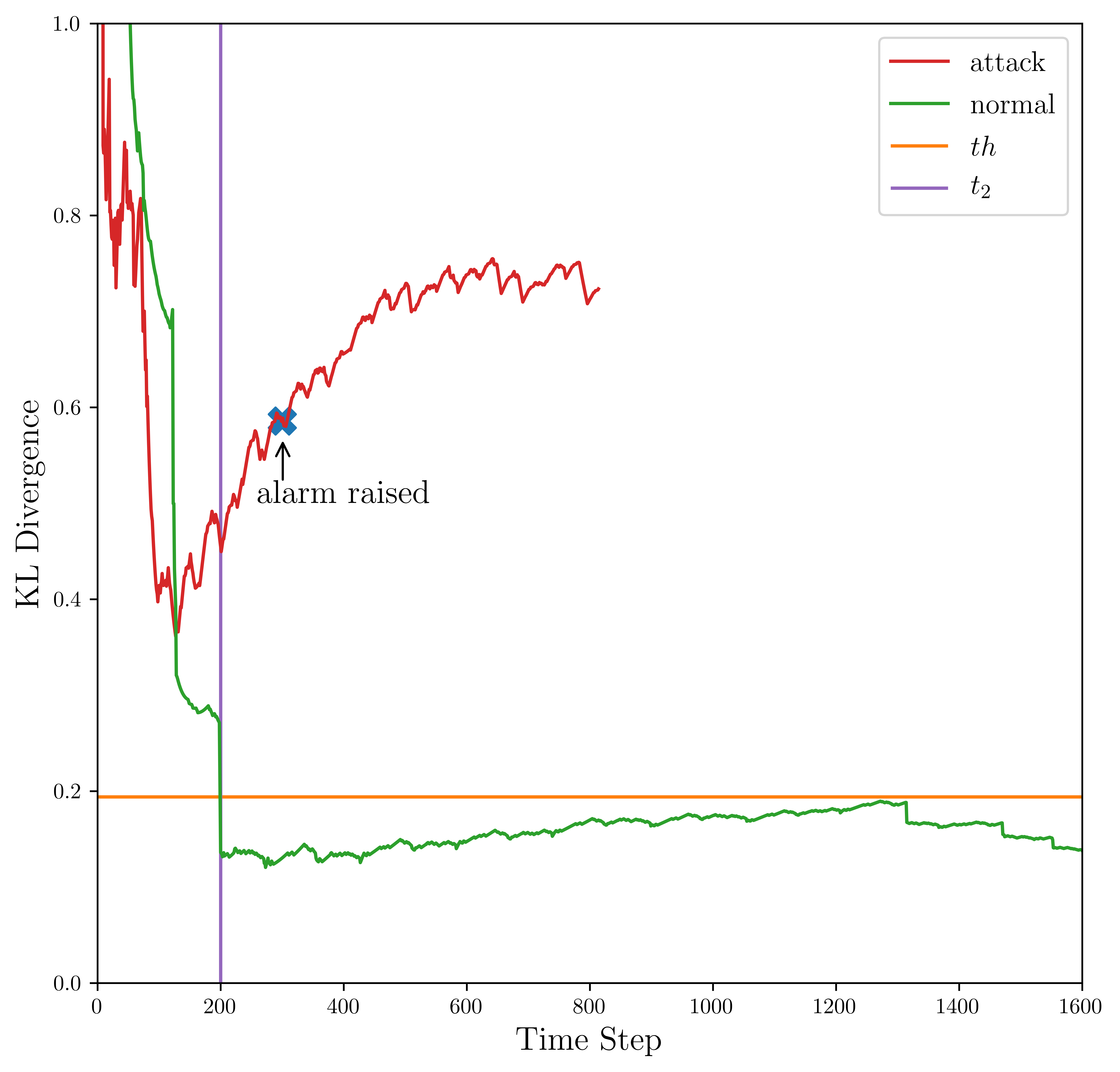
Deep reinforcement learning (DRL) is vulnerable to adversarial perturbations. Adversaries can mislead the policies of DRL agents by perturbing the state of the environment observed by the agents. Existing attacks are feasible in principle, but face challenges in practice, either by being too slow to fool DRL policies in real time or by modifying past observations stored in the agent's memory. We show that Universal Adversarial Perturbations (UAP), independent of the individual inputs to which they are applied, can fool DRL policies effectively and in real time. We introduce three attack variants leveraging UAP. Via an extensive evaluation using three Atari 2600 games, we show that our attacks are effective, as they fully degrade the performance of three different DRL agents (up to 100%, even when the $l_\infty$ bound on the perturbation is as small as 0.01). It is faster than the frame rate (60 Hz) of image capture and considerably faster than prior attacks ($\approx 1.8$ms). Our attack technique is also efficient, incurring an online computational cost of $\approx 0.027$ms. Using two tasks involving robotic movement, we confirm that our results generalize to complex DRL tasks. Furthermore, we demonstrate that the effectiveness of known defenses diminishes against universal perturbations. We introduce an effective technique that detects all known adversarial perturbations against DRL policies, including all universal perturbations presented in this paper.
PDF Abstract


