Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
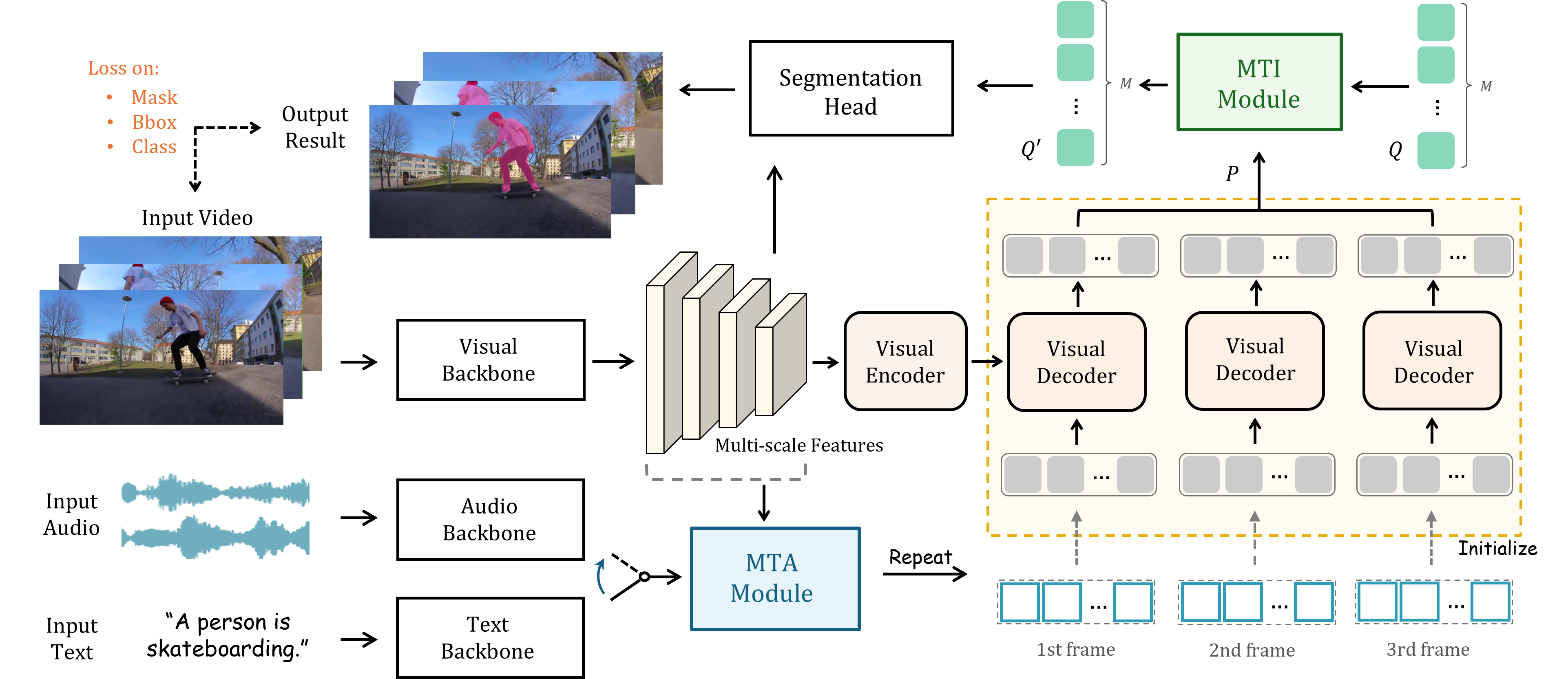
Recently, video object segmentation (VOS) referred by multi-modal signals, e.g., language and audio, has evoked increasing attention in both industry and academia. It is challenging for exploring the semantic alignment within modalities and the visual correspondence across frames. However, existing methods adopt separate network architectures for different modalities, and neglect the inter-frame temporal interaction with references. In this paper, we propose MUTR, a Multi-modal Unified Temporal transformer for Referring video object segmentation. With a unified framework for the first time, MUTR adopts a DETR-style transformer and is capable of segmenting video objects designated by either text or audio reference. Specifically, we introduce two strategies to fully explore the temporal relations between videos and multi-modal signals. Firstly, for low-level temporal aggregation before the transformer, we enable the multi-modal references to capture multi-scale visual cues from consecutive video frames. This effectively endows the text or audio signals with temporal knowledge and boosts the semantic alignment between modalities. Secondly, for high-level temporal interaction after the transformer, we conduct inter-frame feature communication for different object embeddings, contributing to better object-wise correspondence for tracking along the video. On Ref-YouTube-VOS and AVSBench datasets with respective text and audio references, MUTR achieves +4.2% and +8.7% J&F improvements to state-of-the-art methods, demonstrating our significance for unified multi-modal VOS. Code is released at https://github.com/OpenGVLab/MUTR.
PDF Abstract




 RefCOCO
RefCOCO
 YouTube-VOS 2018
YouTube-VOS 2018
 Referring Expressions for DAVIS 2016 & 2017
Referring Expressions for DAVIS 2016 & 2017
 Refer-YouTube-VOS
Refer-YouTube-VOS

