ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
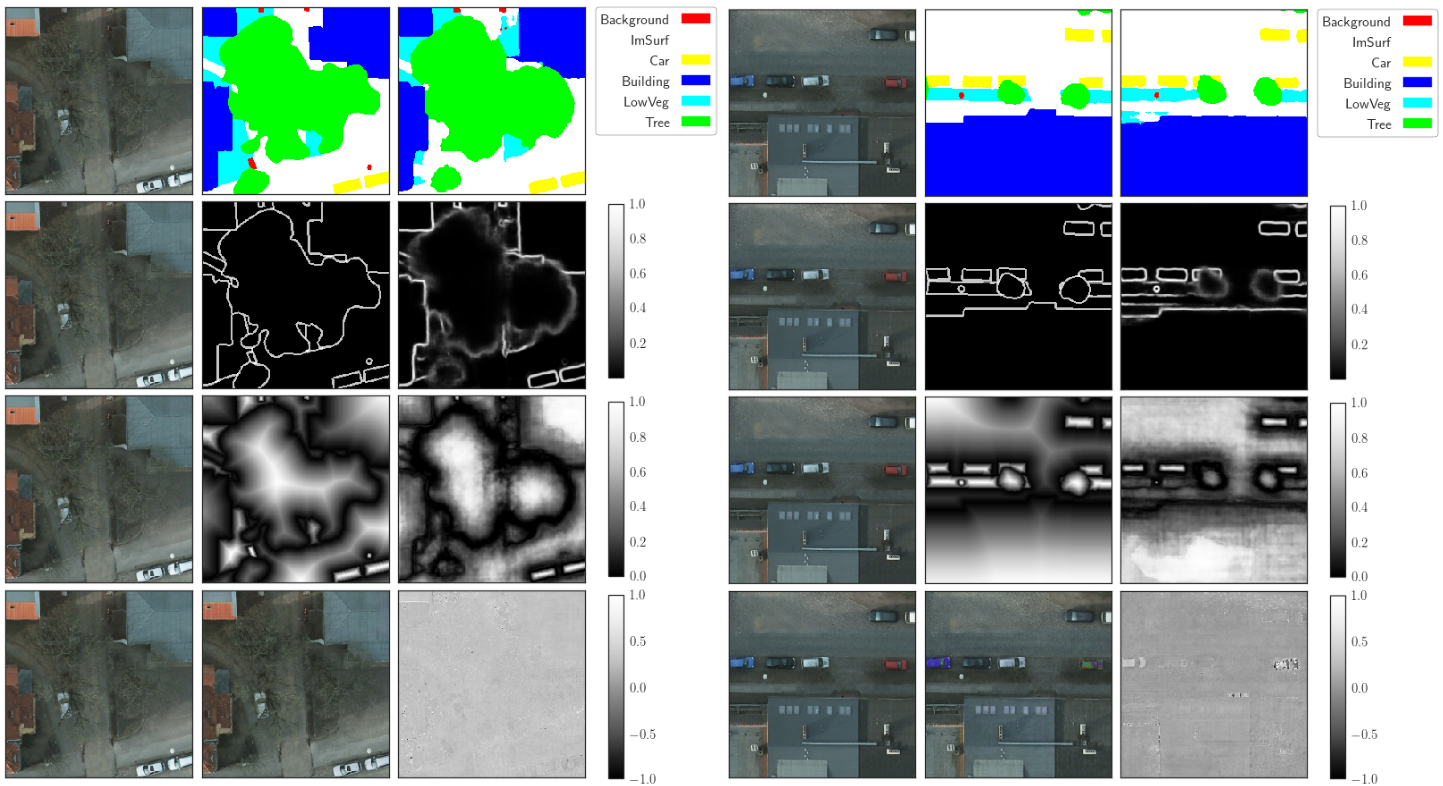
Scene understanding of high resolution aerial images is of great importance for the task of automated monitoring in various remote sensing applications. Due to the large within-class and small between-class variance in pixel values of objects of interest, this remains a challenging task. In recent years, deep convolutional neural networks have started being used in remote sensing applications and demonstrate state of the art performance for pixel level classification of objects. \textcolor{black}{Here we propose a reliable framework for performant results for the task of semantic segmentation of monotemporal very high resolution aerial images. Our framework consists of a novel deep learning architecture, ResUNet-a, and a novel loss function based on the Dice loss. ResUNet-a uses a UNet encoder/decoder backbone, in combination with residual connections, atrous convolutions, pyramid scene parsing pooling and multi-tasking inference. ResUNet-a infers sequentially the boundary of the objects, the distance transform of the segmentation mask, the segmentation mask and a colored reconstruction of the input. Each of the tasks is conditioned on the inference of the previous ones, thus establishing a conditioned relationship between the various tasks, as this is described through the architecture's computation graph. We analyse the performance of several flavours of the Generalized Dice loss for semantic segmentation, and we introduce a novel variant loss function for semantic segmentation of objects that has excellent convergence properties and behaves well even under the presence of highly imbalanced classes.} The performance of our modeling framework is evaluated on the ISPRS 2D Potsdam dataset. Results show state-of-the-art performance with an average F1 score of 92.9\% over all classes for our best model.
PDF Abstract Colab
Colab




