Revisiting Click-based Interactive Video Object Segmentation
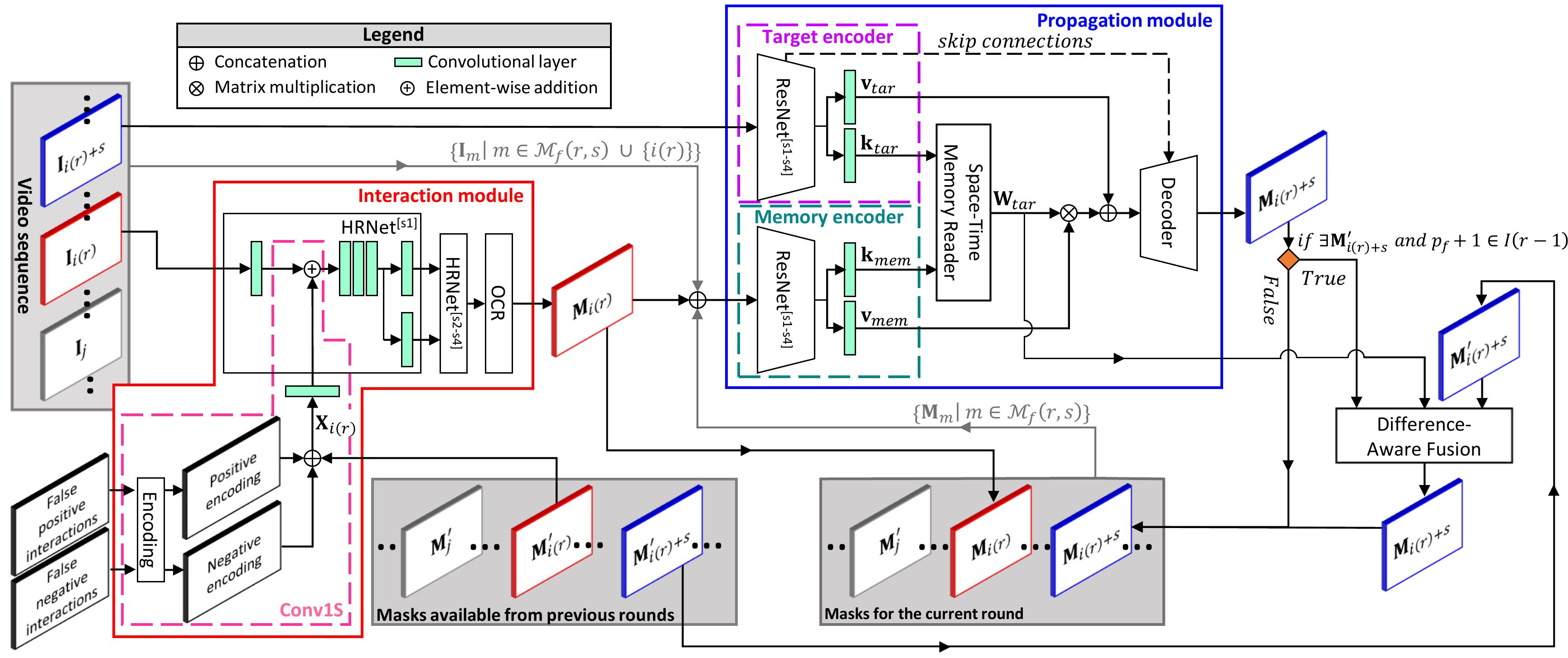
While current methods for interactive Video Object Segmentation (iVOS) rely on scribble-based interactions to generate precise object masks, we propose a Click-based interactive Video Object Segmentation (CiVOS) framework to simplify the required user workload as much as possible. CiVOS builds on de-coupled modules reflecting user interaction and mask propagation. The interaction module converts click-based interactions into an object mask, which is then inferred to the remaining frames by the propagation module. Additional user interactions allow for a refinement of the object mask. The approach is extensively evaluated on the popular interactive~DAVIS dataset, but with an inevitable adaptation of scribble-based interactions with click-based counterparts. We consider several strategies for generating clicks during our evaluation to reflect various user inputs and adjust the DAVIS performance metric to perform a hardware-independent comparison. The presented CiVOS pipeline achieves competitive results, although requiring a lower user workload.
PDF Abstract




 DAVIS
DAVIS
 DAVIS 2017
DAVIS 2017
