RoME: Role-aware Mixture-of-Expert Transformer for Text-to-Video Retrieval
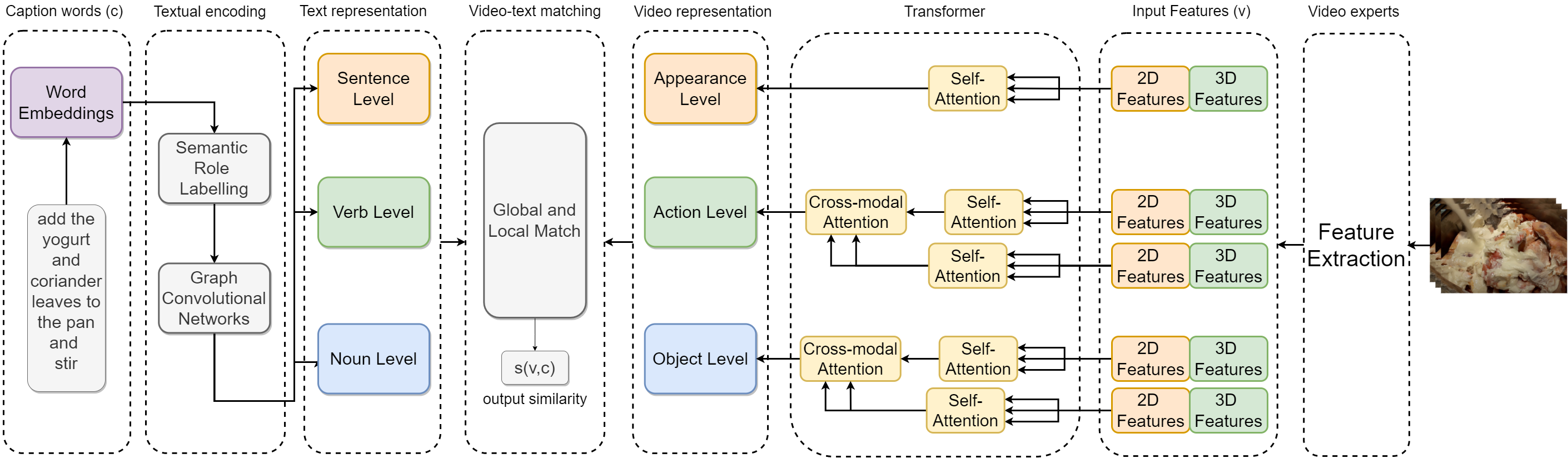
Seas of videos are uploaded daily with the popularity of social channels; thus, retrieving the most related video contents with user textual queries plays a more crucial role. Most methods consider only one joint embedding space between global visual and textual features without considering the local structures of each modality. Some other approaches consider multiple embedding spaces consisting of global and local features separately, ignoring rich inter-modality correlations. We propose a novel mixture-of-expert transformer RoME that disentangles the text and the video into three levels; the roles of spatial contexts, temporal contexts, and object contexts. We utilize a transformer-based attention mechanism to fully exploit visual and text embeddings at both global and local levels with mixture-of-experts for considering inter-modalities and structures' correlations. The results indicate that our method outperforms the state-of-the-art methods on the YouCook2 and MSR-VTT datasets, given the same visual backbone without pre-training. Finally, we conducted extensive ablation studies to elucidate our design choices.
PDF Abstract

 MSR-VTT
MSR-VTT
 YouCook2
YouCook2

