SAM-PD: How Far Can SAM Take Us in Tracking and Segmenting Anything in Videos by Prompt Denoising
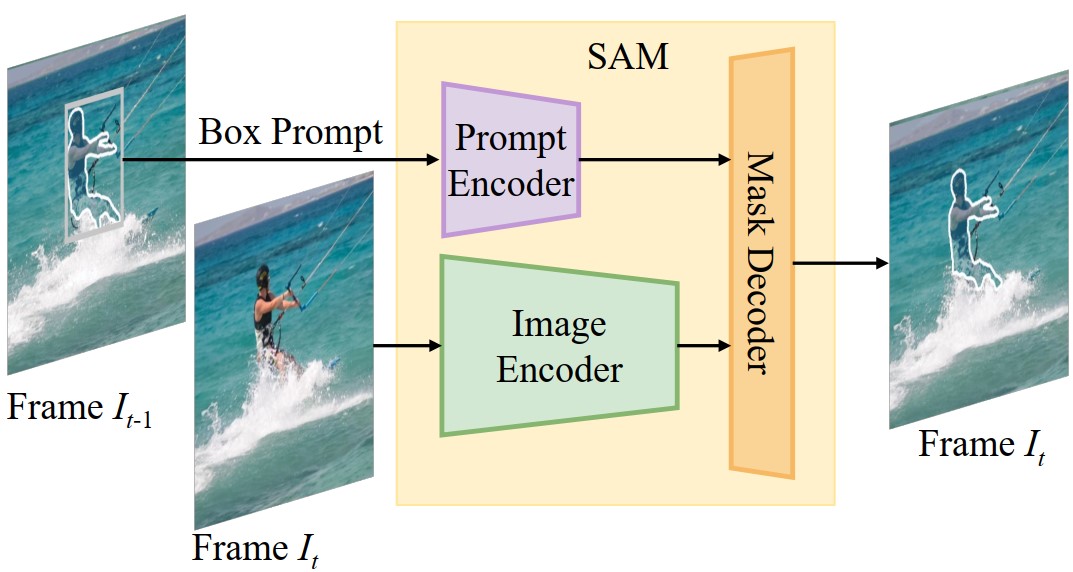
Recently, promptable segmentation models, such as the Segment Anything Model (SAM), have demonstrated robust zero-shot generalization capabilities on static images. These promptable models exhibit denoising abilities for imprecise prompt inputs, such as imprecise bounding boxes. In this paper, we explore the potential of applying SAM to track and segment objects in videos where we recognize the tracking task as a prompt denoising task. Specifically, we iteratively propagate the bounding box of each object's mask in the preceding frame as the prompt for the next frame. Furthermore, to enhance SAM's denoising capability against position and size variations, we propose a multi-prompt strategy where we provide multiple jittered and scaled box prompts for each object and preserve the mask prediction with the highest semantic similarity to the template mask. We also introduce a point-based refinement stage to handle occlusions and reduce cumulative errors. Without involving tracking modules, our approach demonstrates comparable performance in video object/instance segmentation tasks on three datasets: DAVIS2017, YouTubeVOS2018, and UVO, serving as a concise baseline and endowing SAM-based downstream applications with tracking capabilities.
PDF Abstract





 DAVIS 2017
DAVIS 2017
 YouTube-VOS 2018
YouTube-VOS 2018
 UVO
UVO
