Scalable Recommendation of Wikipedia Articles to Editors Using Representation Learning
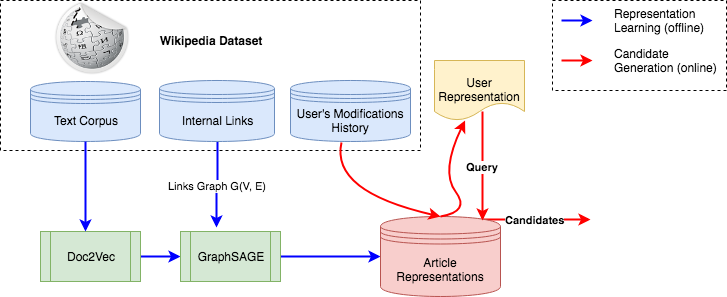
Wikipedia is edited by volunteer editors around the world. Considering the large amount of existing content (e.g. over 5M articles in English Wikipedia), deciding what to edit next can be difficult, both for experienced users that usually have a huge backlog of articles to prioritize, as well as for newcomers who that might need guidance in selecting the next article to contribute. Therefore, helping editors to find relevant articles should improve their performance and help in the retention of new editors. In this paper, we address the problem of recommending relevant articles to editors. To do this, we develop a scalable system on top of Graph Convolutional Networks and Doc2Vec, learning how to represent Wikipedia articles and deliver personalized recommendations for editors. We test our model on editors' histories, predicting their most recent edits based on their prior edits. We outperform competitive implicit-feedback collaborative-filtering methods such as WMRF based on ALS, as well as a traditional IR-method such as content-based filtering based on BM25. All of the data used on this paper is publicly available, including graph embeddings for Wikipedia articles, and we release our code to support replication of our experiments. Moreover, we contribute with a scalable implementation of a state-of-art graph embedding algorithm as current ones cannot efficiently handle the sheer size of the Wikipedia graph.
PDF Abstract


