Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
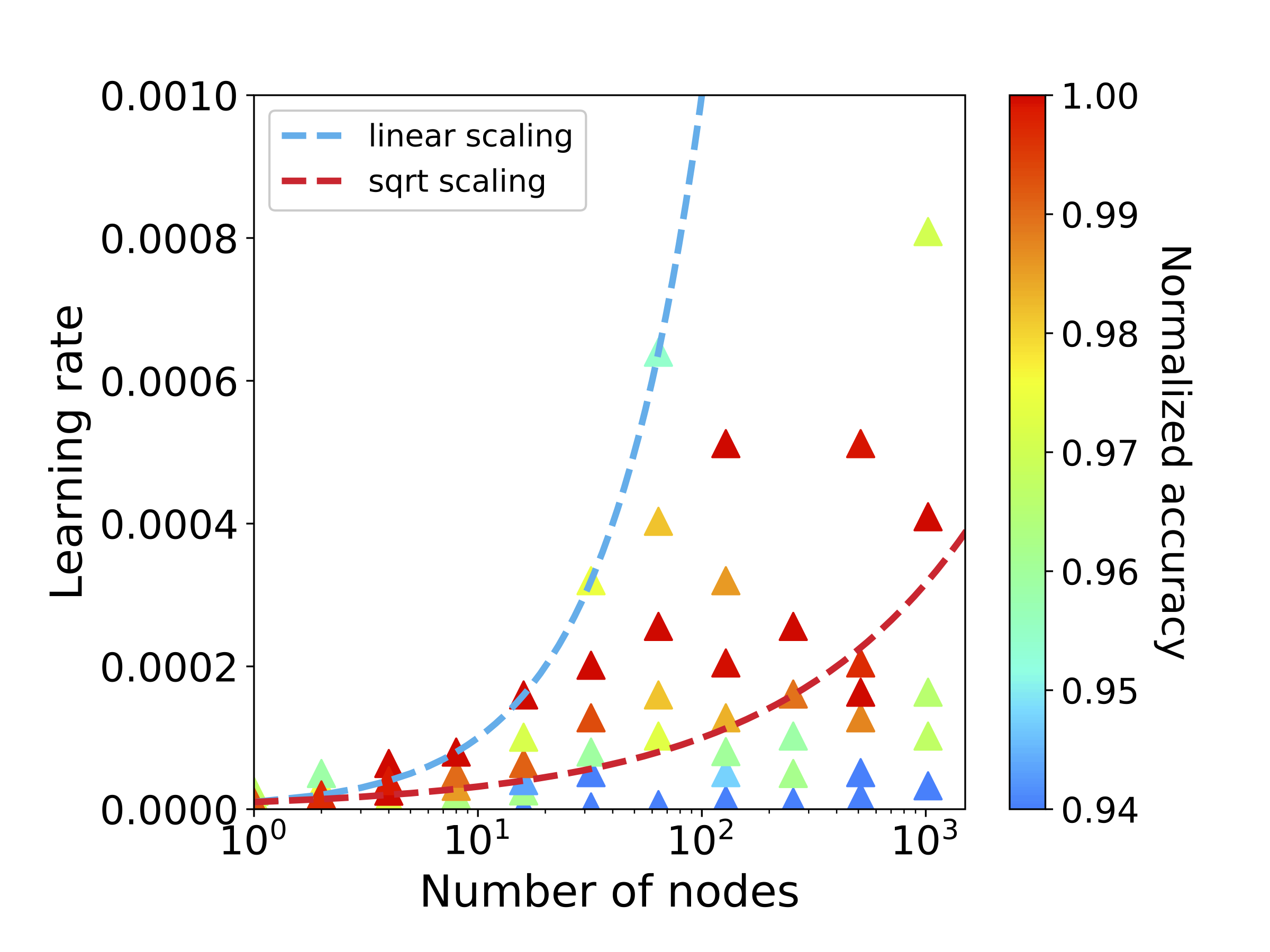
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. The flood-filling network (FFN) architecture has demonstrated leading performance for segmenting structures from this data. However, the training of the network is computationally expensive. In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod library, which is different from the asynchronous training scheme used in the published FFN code. We demonstrated that our distributed training scaled well up to 2048 Intel Knights Landing (KNL) nodes on the Theta supercomputer. Our trained models achieved similar level of inference performance, but took less training time compared to previous methods. Our study on the effects of different batch sizes on FFN training suggests ways to further improve training efficiency. Our findings on optimal learning rate and batch sizes agree with previous works.
PDF Abstract

