SD-HuBERT: Sentence-Level Self-Distillation Induces Syllabic Organization in HuBERT
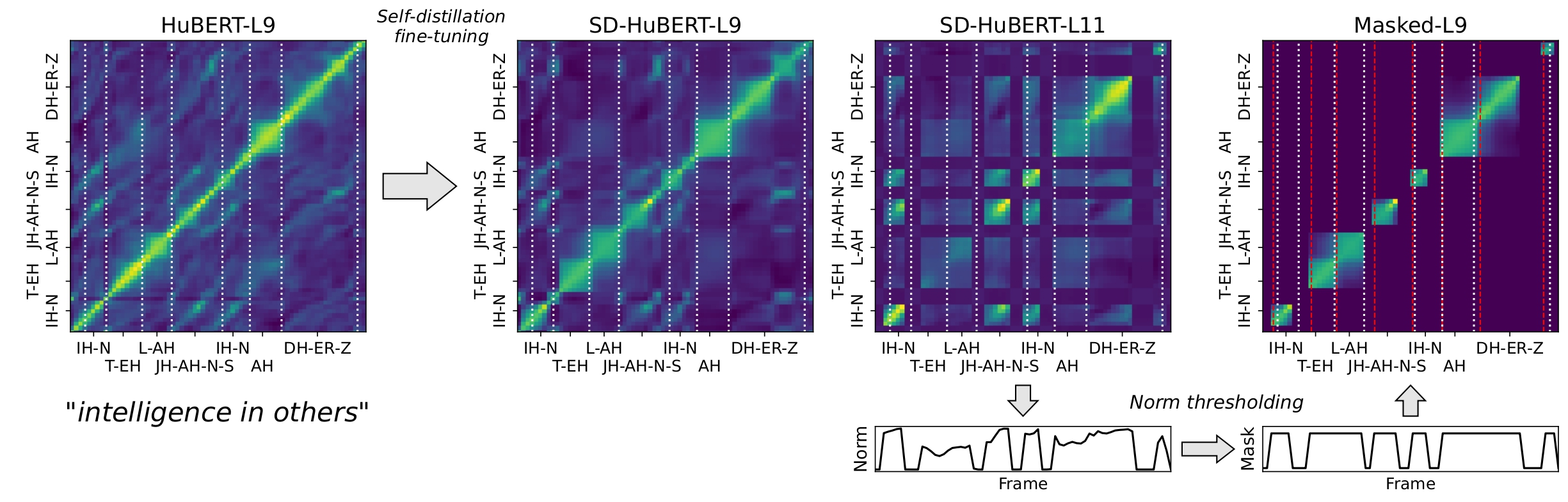
Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space and the units beyond phonemes are largely underexplored. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames exhibit salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
PDF Abstract



 LibriSpeech
LibriSpeech
