Self-Supervised 3D Human Pose Estimation with Multiple-View Geometry
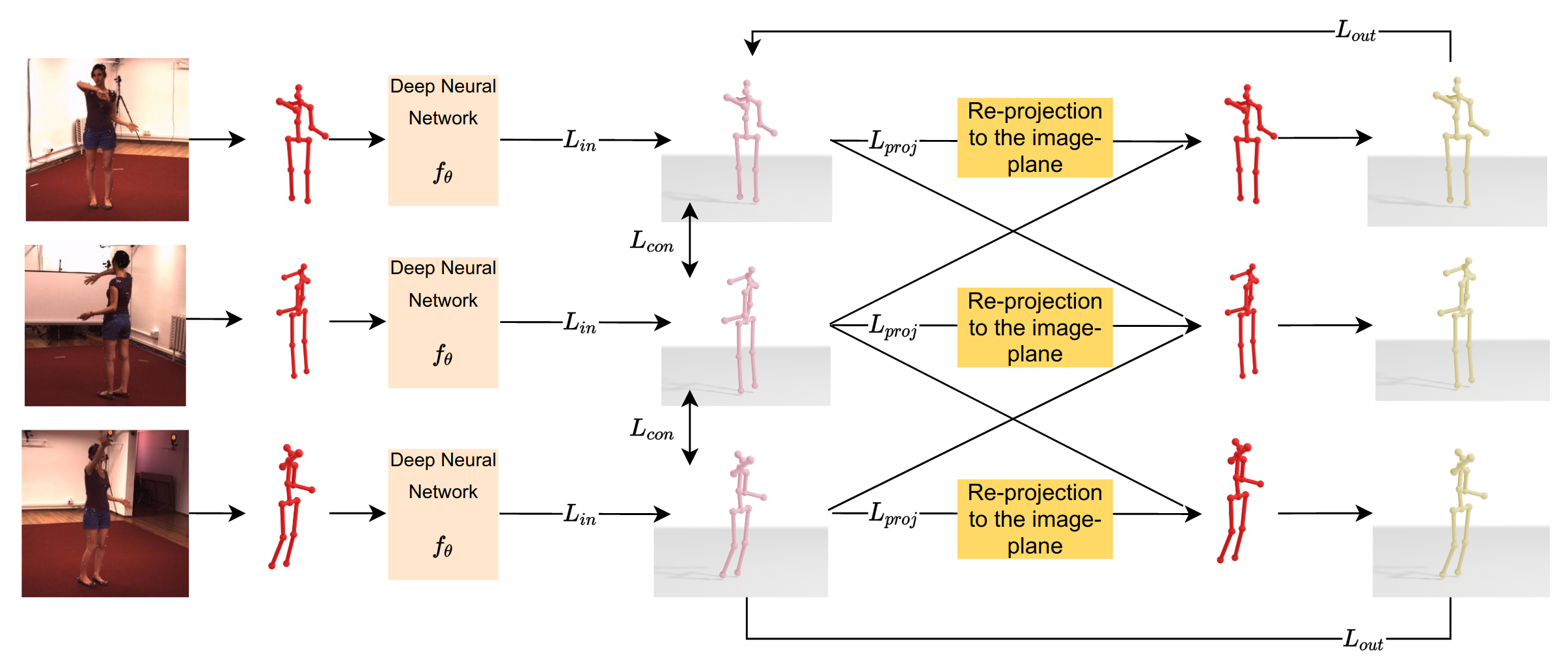
We present a self-supervised learning algorithm for 3D human pose estimation of a single person based on a multiple-view camera system and 2D body pose estimates for each view. To train our model, represented by a deep neural network, we propose a four-loss function learning algorithm, which does not require any 2D or 3D body pose ground-truth. The proposed loss functions make use of the multiple-view geometry to reconstruct 3D body pose estimates and impose body pose constraints across the camera views. Our approach utilizes all available camera views during training, while the inference is single-view. In our evaluations, we show promising performance on Human3.6M and HumanEva benchmarks, while we also present a generalization study on MPI-INF-3DHP dataset, as well as several ablation results. Overall, we outperform all self-supervised learning methods and reach comparable results to supervised and weakly-supervised learning approaches. Our code and models are publicly available
PDF Abstract




 Human3.6M
Human3.6M

