Self-Supervised Learning for speech recognition with Intermediate layer supervision
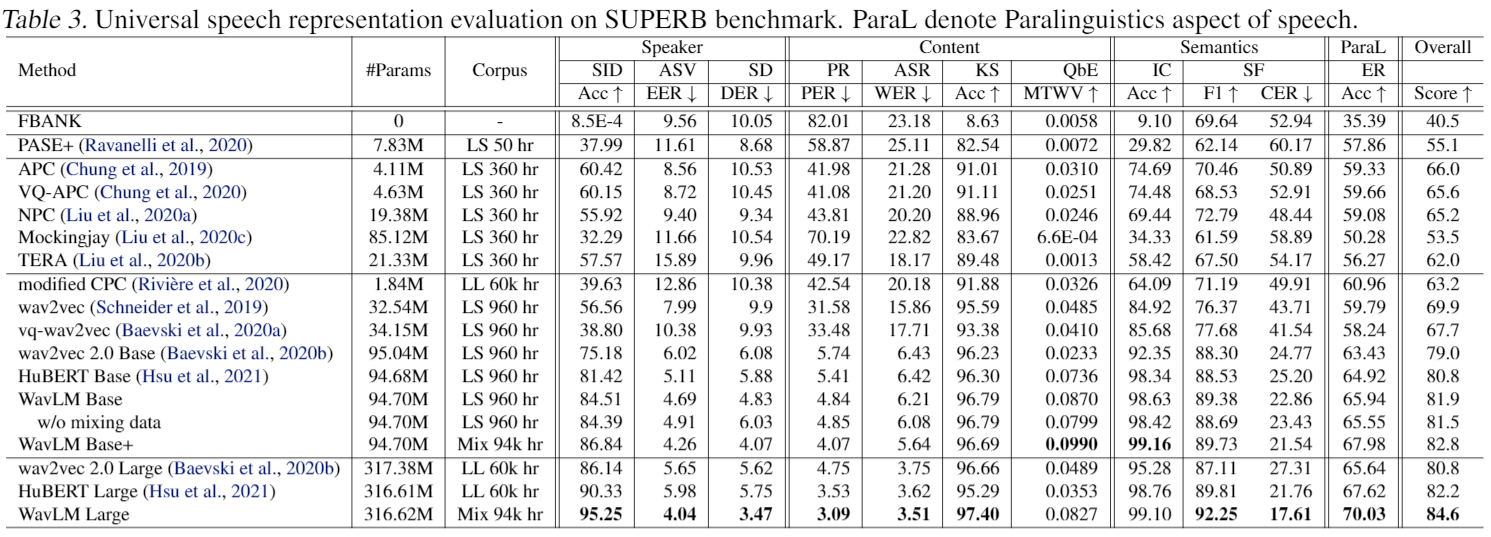
Recently, pioneer work finds that speech pre-trained models can solve full-stack speech processing tasks, because the model utilizes bottom layers to learn speaker-related information and top layers to encode content-related information. Since the network capacity is limited, we believe the speech recognition performance could be further improved if the model is dedicated to audio content information learning. To this end, we propose Intermediate Layer Supervision for Self-Supervised Learning (ILS-SSL), which forces the model to concentrate on content information as much as possible by adding an additional SSL loss on the intermediate layers. Experiments on LibriSpeech test-other set show that our method outperforms HuBERT significantly, which achieves a 23.5%/11.6% relative word error rate reduction in the w/o language model setting for base/large models. Detailed analysis shows the bottom layers of our model have a better correlation with phonetic units, which is consistent with our intuition and explains the success of our method for ASR.
PDF Abstract




 LibriSpeech
LibriSpeech
