Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
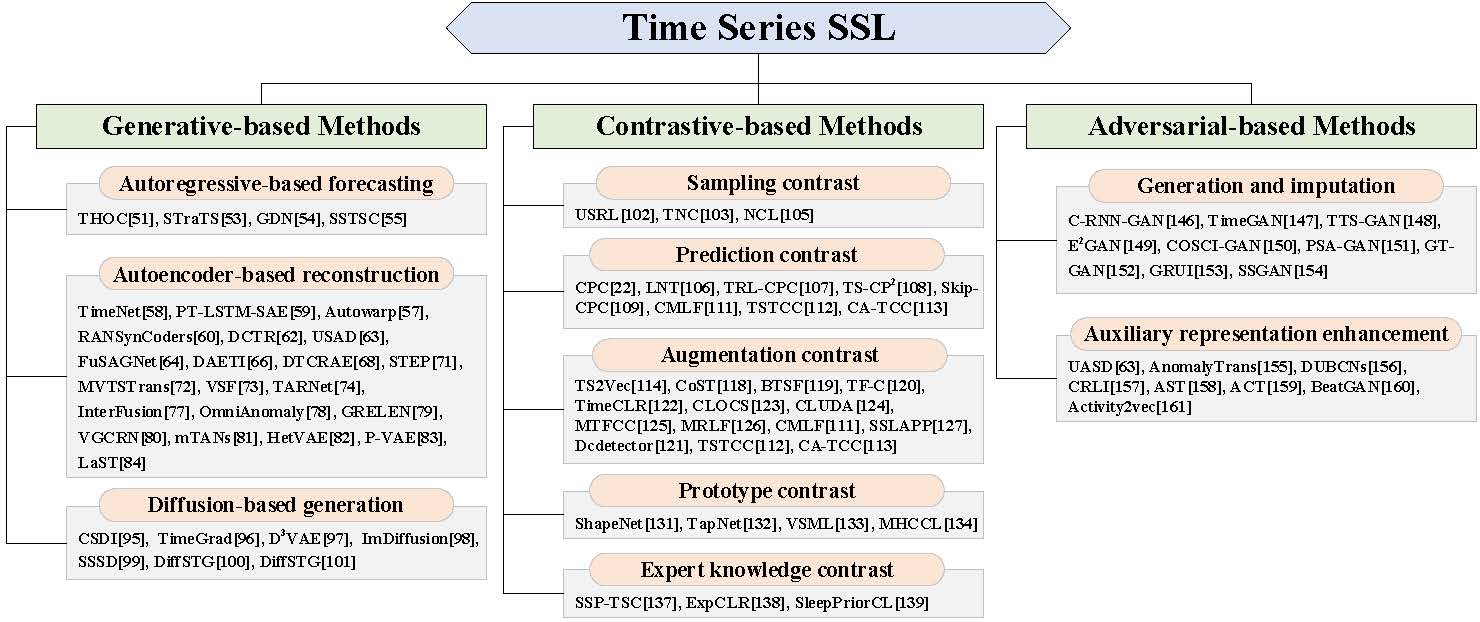
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods by summarizing them from three perspectives: generative-based, contrastive-based, and adversarial-based. These methods are further divided into ten subcategories with detailed reviews and discussions about their key intuitions, main frameworks, advantages and disadvantages. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
PDF Abstract




