Semantic Graph Convolutional Networks for 3D Human Pose Regression
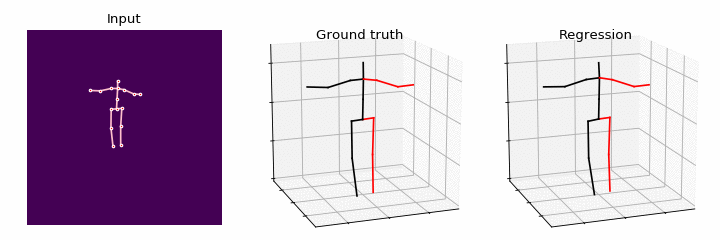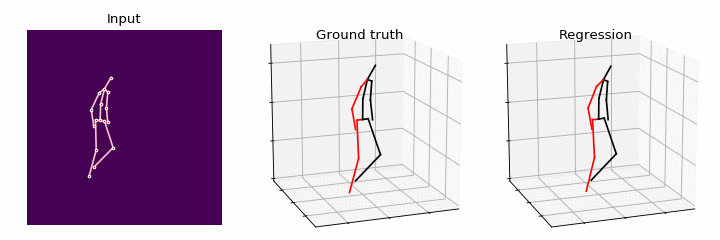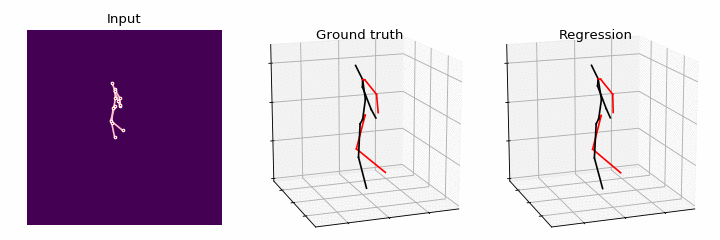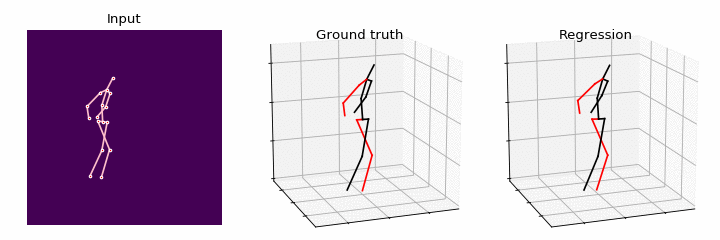
In this paper, we study the problem of learning Graph Convolutional Networks (GCNs) for regression. Current architectures of GCNs are limited to the small receptive field of convolution filters and shared transformation matrix for each node. To address these limitations, we propose Semantic Graph Convolutional Networks (SemGCN), a novel neural network architecture that operates on regression tasks with graph-structured data. SemGCN learns to capture semantic information such as local and global node relationships, which is not explicitly represented in the graph. These semantic relationships can be learned through end-to-end training from the ground truth without additional supervision or hand-crafted rules. We further investigate applying SemGCN to 3D human pose regression. Our formulation is intuitive and sufficient since both 2D and 3D human poses can be represented as a structured graph encoding the relationships between joints in the skeleton of a human body. We carry out comprehensive studies to validate our method. The results prove that SemGCN outperforms state of the art while using 90% fewer parameters.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract


 ImageNet
ImageNet
 Human3.6M
Human3.6M
 MPII
MPII

