Leveraging Category Information for Single-Frame Visual Sound Source Separation
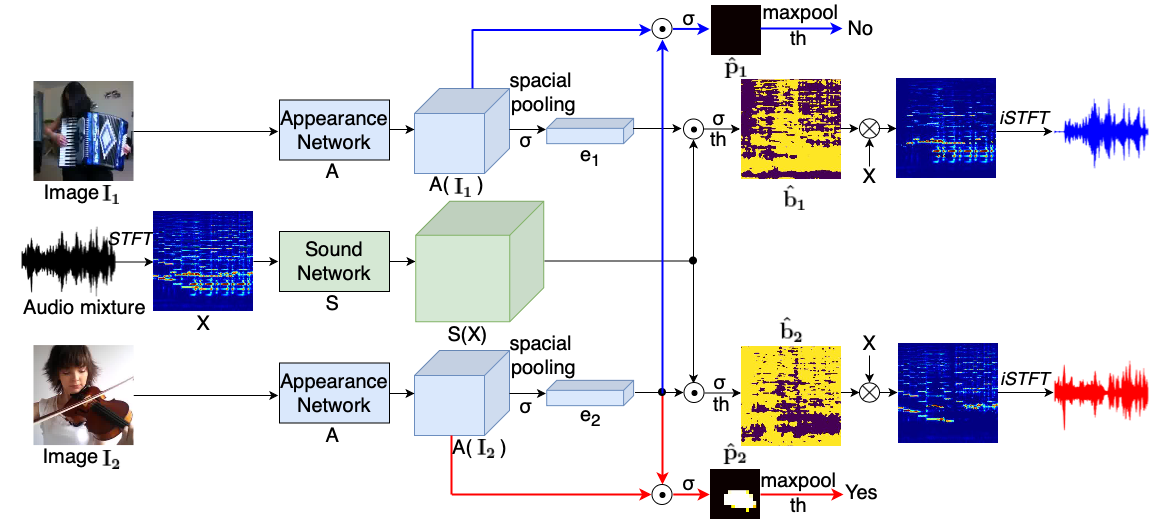
Visual sound source separation aims at identifying sound components from a given sound mixture with the presence of visual cues. Prior works have demonstrated impressive results, but with the expense of large multi-stage architectures and complex data representations (e.g. optical flow trajectories). In contrast, we study simple yet efficient models for visual sound separation using only a single video frame. Furthermore, our models are able to exploit the information of the sound source category in the separation process. To this end, we propose two models where we assume that i) the category labels are available at the training time, or ii) we know if the training sample pairs are from the same or different category. The experiments with the MUSIC dataset show that our model obtains comparable or better performance compared to several recent baseline methods. The code is available at https://github.com/ly-zhu/Leveraging-Category-Information-for-Single-Frame-Visual-Sound-Source-Separation
PDF Abstract

