Unified Sequence-to-Sequence Learning for Single- and Multi-Modal Visual Object Tracking
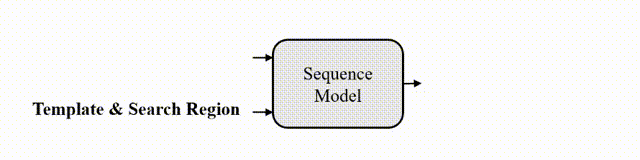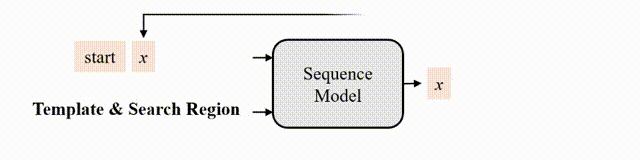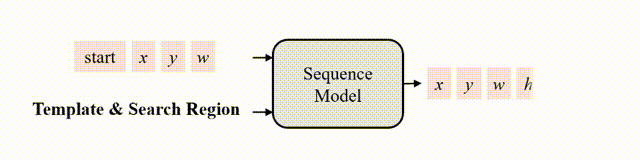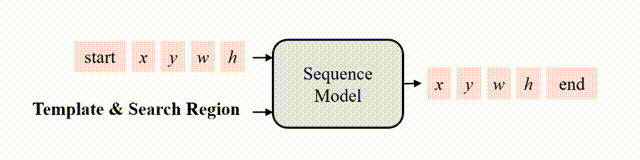
In this paper, we introduce a new sequence-to-sequence learning framework for RGB-based and multi-modal object tracking. First, we present SeqTrack for RGB-based tracking. It casts visual tracking as a sequence generation task, forecasting object bounding boxes in an autoregressive manner. This differs from previous trackers, which depend on the design of intricate head networks, such as classification and regression heads. SeqTrack employs a basic encoder-decoder transformer architecture. The encoder utilizes a bidirectional transformer for feature extraction, while the decoder generates bounding box sequences autoregressively using a causal transformer. The loss function is a plain cross-entropy. Second, we introduce SeqTrackv2, a unified sequence-to-sequence framework for multi-modal tracking tasks. Expanding upon SeqTrack, SeqTrackv2 integrates a unified interface for auxiliary modalities and a set of task-prompt tokens to specify the task. This enables it to manage multi-modal tracking tasks using a unified model and parameter set. This sequence learning paradigm not only simplifies the tracking framework, but also showcases superior performance across 14 challenging benchmarks spanning five single- and multi-modal tracking tasks. The code and models are available at https://github.com/chenxin-dlut/SeqTrackv2.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 OTB
OTB
 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
 OTB-2015
OTB-2015
 TNL2K
TNL2K
 LasHeR
LasHeR
 RGBT234
RGBT234
 VisEvent
VisEvent
