ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
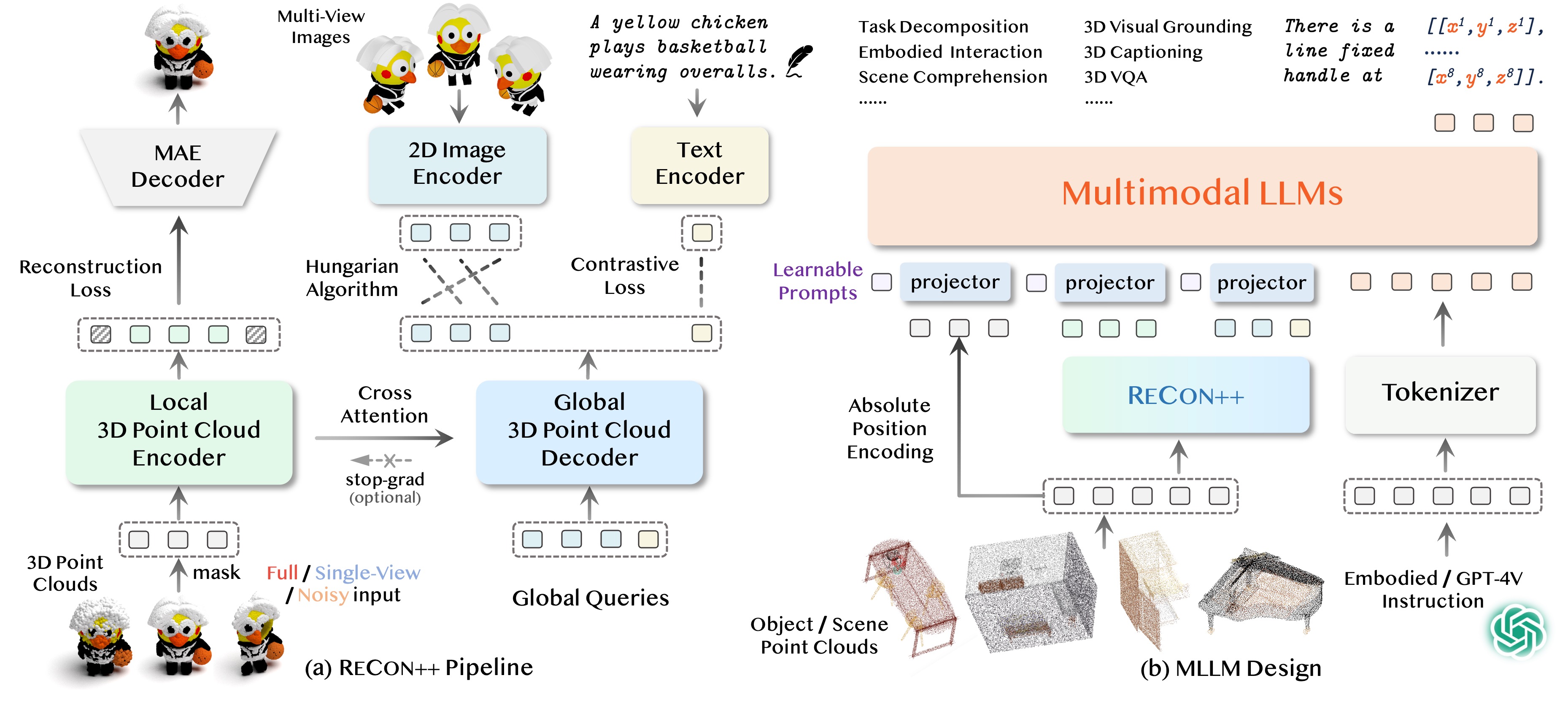
This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.
PDF AbstractCode

Tasks
 3D Object Captioning
3D Object Captioning
 3D Point Cloud Classification
3D Point Cloud Linear Classification
3D Point Cloud Classification
3D Point Cloud Linear Classification
 3D Question Answering (3D-QA)
Few-Shot 3D Point Cloud Classification
Generative 3D Object Classification
Instruction Following
3D Question Answering (3D-QA)
Few-Shot 3D Point Cloud Classification
Generative 3D Object Classification
Instruction Following
 Language Modelling
Large Language Model
Object
Language Modelling
Large Language Model
Object
 Visual Grounding
Zero-shot 3D classification
Zero-Shot Transfer 3D Point Cloud Classification
Visual Grounding
Zero-shot 3D classification
Zero-Shot Transfer 3D Point Cloud Classification
 3D MM-Vet
3D MM-Vet
 ShapeNet
ShapeNet
 ModelNet
ModelNet
 LVIS
LVIS
 ScanObjectNN
ScanObjectNN
 Objaverse
Objaverse

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| 3D Question Answering (3D-QA) | 3D MM-Vet | ShapeLLM-13B | Overall Accuracy | 53.1 | # 1 | ||
| 3D Question Answering (3D-QA) | 3D MM-Vet | ShapeLLM-7B | Overall Accuracy | 47.4 | # 2 | ||
| 3D Point Cloud Linear Classification | ModelNet40 | ReCon++ | Overall Accuracy | 93.6 | # 1 | ||
| Generative 3D Object Classification | ModelNet40 | ShapeLLM-13B | ModelNet40 (Average) | 52.96 | # 2 | ||
| LLM Size | 13B | # 1 | |||||
| Generative 3D Object Classification | ModelNet40 | ShapeLLM-7B | ModelNet40 (Average) | 53.08 | # 1 | ||
| LLM Size | 7B | # 1 | |||||
| 3D Point Cloud Classification | ModelNet40 | ReCon++ | Overall Accuracy | 95.0 | # 4 | ||
| Zero-Shot Transfer 3D Point Cloud Classification | ModelNet40 | ReCon++ | Accuracy (%) | 87.3 | # 3 | ||
| Few-Shot 3D Point Cloud Classification | ModelNet40 10-way (10-shot) | ReCon++ | Overall Accuracy | 94.5 | # 1 | ||
| Standard Deviation | 4.1 | # 13 | |||||
| Few-Shot 3D Point Cloud Classification | ModelNet40 10-way (20-shot) | ReCon++ | Overall Accuracy | 96.5 | # 1 | ||
| Standard Deviation | 3.0 | # 10 | |||||
| Few-Shot 3D Point Cloud Classification | ModelNet40 5-way (10-shot) | ReCon++ | Overall Accuracy | 98.0 | # 1 | ||
| Standard Deviation | 2.3 | # 11 | |||||
| Few-Shot 3D Point Cloud Classification | ModelNet40 5-way (20-shot) | ReCon++ | Overall Accuracy | 99.5 | # 1 | ||
| Standard Deviation | 0.8 | # 1 | |||||
| 3D Object Captioning | Objaverse | ShapeLLM-13B | GPT-4 | 48.94 | # 1 | ||
| Sentence-BERT | 48.52 | # 1 | |||||
| SimCSE | 49.98 | # 1 | |||||
| LLM Size (B) | 13 | # 3 | |||||
| 3D Object Captioning | Objaverse | ShapeLLM-7B | GPT-4 | 46.92 | # 3 | ||
| Sentence-BERT | 48.20 | # 2 | |||||
| SimCSE | 49.23 | # 2 | |||||
| LLM Size (B) | 7 | # 1 | |||||
| Generative 3D Object Classification | Objaverse | ShapeLLM-7B | Objaverse (Average) | 54.50 | # 1 | ||
| Generative 3D Object Classification | Objaverse | ShapeLLM-13B | Objaverse (Average) | 54.00 | # 2 | ||
| Zero-shot 3D classification | Objaverse LVIS | ReCon++ | Top 1 Accuracy | 53.7 | # 3 | ||
| Zero-Shot Transfer 3D Point Cloud Classification | ScanObjectNN | ReCon++ | OBJ_ONLY Accuracy(%) | 65.4 | # 1 | ||
| 3D Point Cloud Classification | ScanObjectNN | ReCon++ | Overall Accuracy | 95.25 | # 2 | ||
| OBJ-BG (OA) | 97.59 | # 1 | |||||
| OBJ-ONLY (OA) | 98.80 | # 1 |
Methods
No methods listed for this paper. Add
relevant methods here
