Skeleton-based Action Recognition via Adaptive Cross-Form Learning
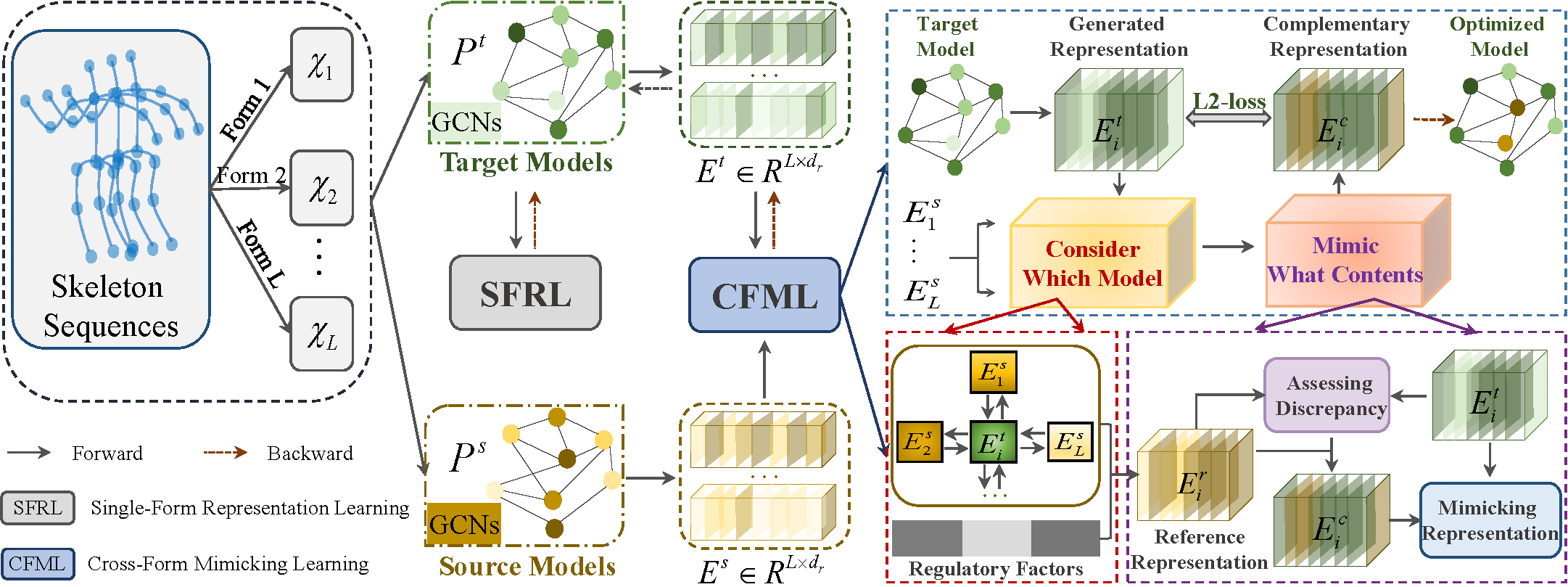
Skeleton-based action recognition aims to project skeleton sequences to action categories, where skeleton sequences are derived from multiple forms of pre-detected points. Compared with earlier methods that focus on exploring single-form skeletons via Graph Convolutional Networks (GCNs), existing methods tend to improve GCNs by leveraging multi-form skeletons due to their complementary cues. However, these methods (either adapting structure of GCNs or model ensemble) require the co-existence of all forms of skeletons during both training and inference stages, while a typical situation in real life is the existence of only partial forms for inference. To tackle this issue, we present Adaptive Cross-Form Learning (ACFL), which empowers well-designed GCNs to generate complementary representation from single-form skeletons without changing model capacity. Specifically, each GCN model in ACFL not only learns action representation from the single-form skeletons, but also adaptively mimics useful representations derived from other forms of skeletons. In this way, each GCN can learn how to strengthen what has been learned, thus exploiting model potential and facilitating action recognition as well. Extensive experiments conducted on three challenging benchmarks, i.e., NTU-RGB+D 120, NTU-RGB+D 60 and UAV-Human, demonstrate the effectiveness and generalizability of the proposed method. Specifically, the ACFL significantly improves various GCN models (i.e., CTR-GCN, MS-G3D, and Shift-GCN), achieving a new record for skeleton-based action recognition.
PDF Abstract


 NTU RGB+D
NTU RGB+D
 UAV-Human
UAV-Human
