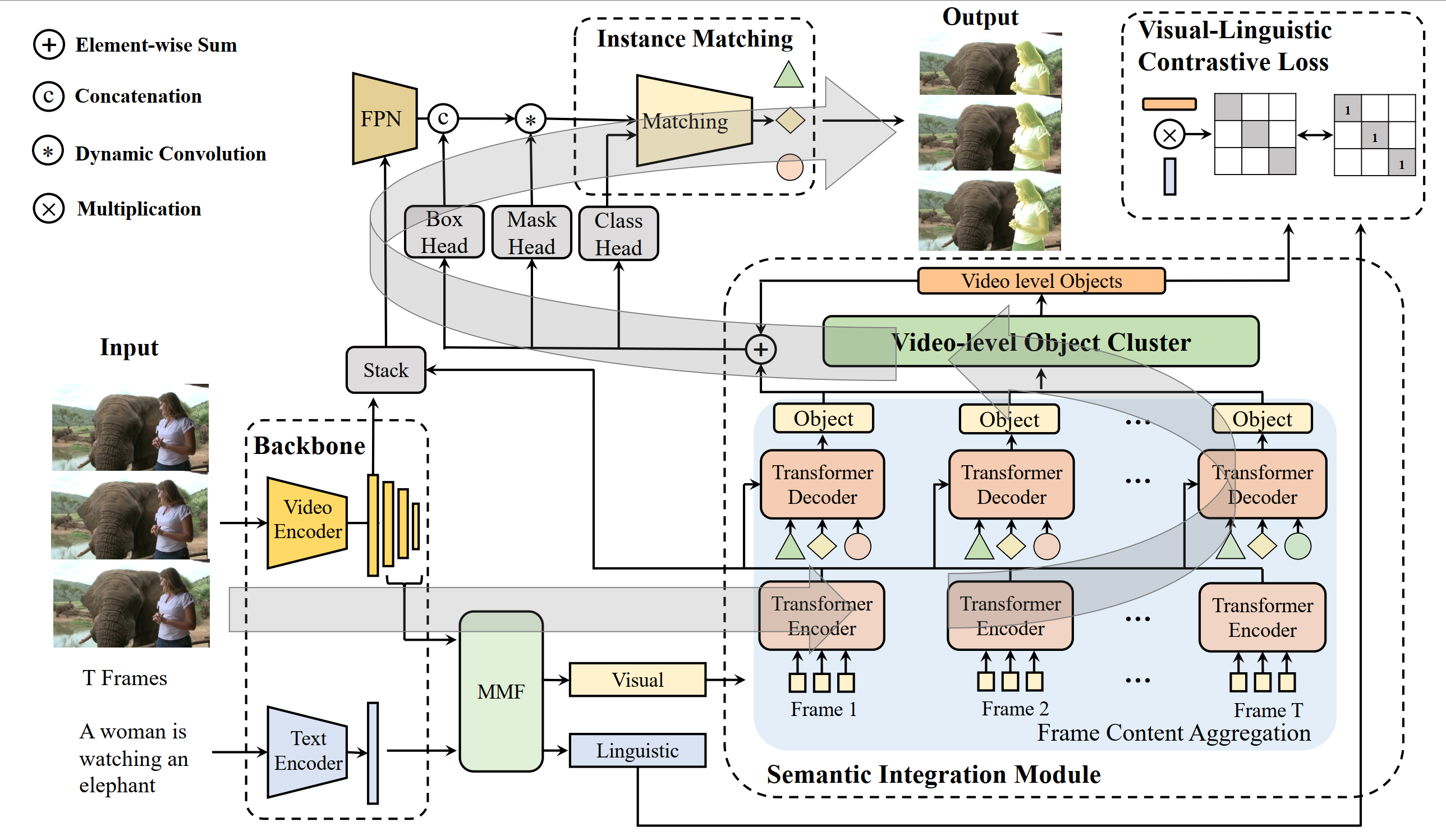
SOC: Semantic-Assisted Object Cluster for Referring Video Object Segmentation
This paper studies referring video object segmentation (RVOS) by boosting video-level visual-linguistic alignment. Recent approaches model the RVOS task as a sequence prediction problem and perform multi-modal interaction as well as segmentation for each frame separately. However, the lack of a global view of video content leads to difficulties in effectively utilizing inter-frame relationships and understanding textual descriptions of object temporal variations. To address this issue, we propose Semantic-assisted Object Cluster (SOC), which aggregates video content and textual guidance for unified temporal modeling and cross-modal alignment. By associating a group of frame-level object embeddings with language tokens, SOC facilitates joint space learning across modalities and time steps. Moreover, we present multi-modal contrastive supervision to help construct well-aligned joint space at the video level. We conduct extensive experiments on popular RVOS benchmarks, and our method outperforms state-of-the-art competitors on all benchmarks by a remarkable margin. Besides, the emphasis on temporal coherence enhances the segmentation stability and adaptability of our method in processing text expressions with temporal variations. Code will be available.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract




Datasets
 JHMDB
JHMDB
 Refer-YouTube-VOS
Refer-YouTube-VOS
 A2D Sentences
A2D Sentences
Results from the Paper
 Ranked #2 on
Referring Expression Segmentation
on A2D Sentences
(using extra training data)
Ranked #2 on
Referring Expression Segmentation
on A2D Sentences
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Referring Expression Segmentation | A2D Sentences | SOC (Video-Swin-T) | Precision@0.5 | 0.79 | # 4 | ||
| Precision@0.9 | 0.195 | # 4 | |||||
| IoU overall | 0.747 | # 4 | |||||
| IoU mean | 0.669 | # 4 | |||||
| Precision@0.6 | 0.756 | # 4 | |||||
| Precision@0.7 | 0.687 | # 4 | |||||
| Precision@0.8 | 0.535 | # 4 | |||||
| AP | 0.504 | # 4 | |||||
| Referring Expression Segmentation | A2D Sentences | SOC (Video-Swin-B) | Precision@0.5 | 0.851 | # 1 | ||
| Precision@0.9 | 0.252 | # 2 | |||||
| IoU overall | 0.807 | # 1 | |||||
| IoU mean | 0.725 | # 1 | |||||
| Precision@0.6 | 0.827 | # 1 | |||||
| Precision@0.7 | 0.765 | # 2 | |||||
| Precision@0.8 | 0.607 | # 2 | |||||
| AP | 0.573 | # 2 | |||||
| Referring Expression Segmentation | J-HMDB | SOC (Video-Swin-B) | Precision@0.5 | 0.969 | # 2 | ||
| Precision@0.6 | 0.914 | # 2 | |||||
| Precision@0.7 | 0.711 | # 2 | |||||
| Precision@0.8 | 0.213 | # 2 | |||||
| Precision@0.9 | 0.001 | # 5 | |||||
| AP | 0.446 | # 2 | |||||
| IoU overall | 0.736 | # 2 | |||||
| IoU mean | 0.723 | # 2 | |||||
| Referring Expression Segmentation | J-HMDB | SOC (Video-Swin-T) | Precision@0.5 | 0.947 | # 3 | ||
| Precision@0.6 | 0.864 | # 3 | |||||
| Precision@0.7 | 0.627 | # 3 | |||||
| Precision@0.8 | 0.179 | # 4 | |||||
| Precision@0.9 | 0.001 | # 5 | |||||
| AP | 0.397 | # 4 | |||||
| IoU overall | 0.707 | # 3 | |||||
| IoU mean | 0.701 | # 3 | |||||
| Referring Video Object Segmentation | Refer-YouTube-VOS | SOC | J&F | 66.0 | # 4 | ||
| J | 64.1 | # 4 | |||||
| F | 67.9 | # 4 | |||||
| Referring Expression Segmentation | Refer-YouTube-VOS (2021 public validation) | SOC (Joint training, Video-Swin-B) | J&F | 67.3±0.5 | # 5 | ||
| J | 65.3 | # 5 | |||||
| F | 69.3 | # 4 | |||||
| Referring Expression Segmentation | Refer-YouTube-VOS (2021 public validation) | SOC (Video-Swin-T) | J&F | 59.2 | # 16 | ||
| J | 57.8 | # 15 | |||||
| F | 60.5 | # 15 |
