Speaker Anonymization with Phonetic Intermediate Representations
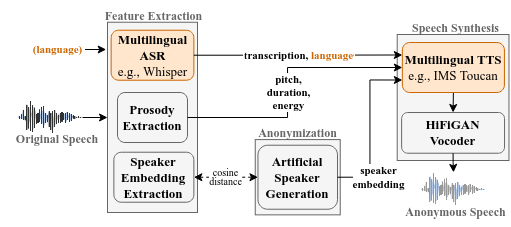
In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
PDF Abstract Spaces
Spaces




 LibriSpeech
LibriSpeech
