Stage-wise Fine-tuning for Graph-to-Text Generation
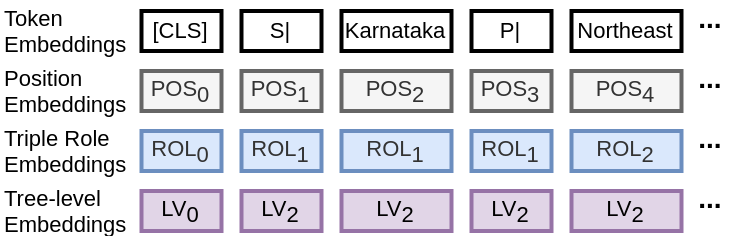
Graph-to-text generation has benefited from pre-trained language models (PLMs) in achieving better performance than structured graph encoders. However, they fail to fully utilize the structure information of the input graph. In this paper, we aim to further improve the performance of the pre-trained language model by proposing a structured graph-to-text model with a two-step fine-tuning mechanism which first fine-tunes the model on Wikipedia before adapting to the graph-to-text generation. In addition to using the traditional token and position embeddings to encode the knowledge graph (KG), we propose a novel tree-level embedding method to capture the inter-dependency structures of the input graph. This new approach has significantly improved the performance of all text generation metrics for the English WebNLG 2017 dataset.
PDF Abstract ACL 2021 PDF ACL 2021 Abstract




Datasets
 WebNLG
WebNLG
Results from the Paper
 Ranked #3 on
Data-to-Text Generation
on WebNLG
(using extra training data)
Ranked #3 on
Data-to-Text Generation
on WebNLG
(using extra training data)
