SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners
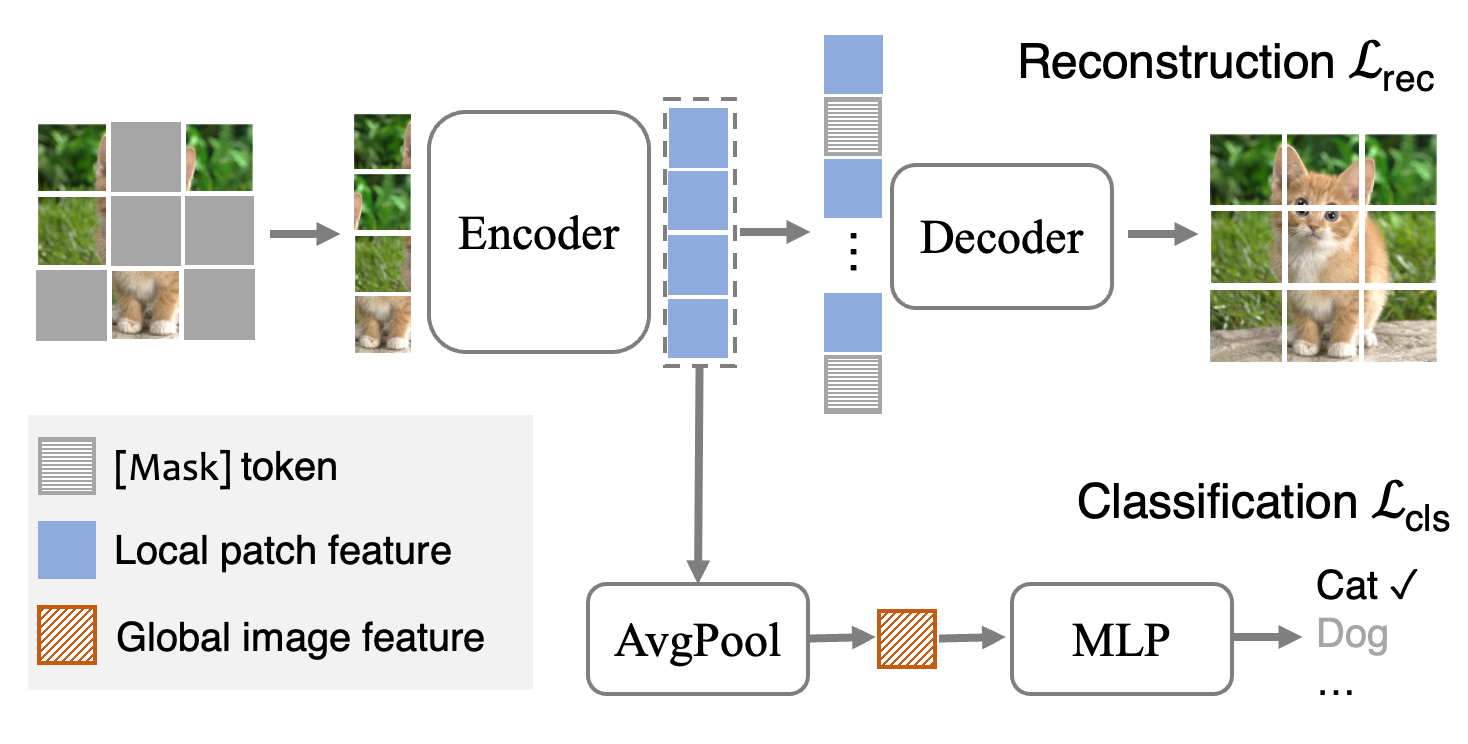
Recently, self-supervised Masked Autoencoders (MAE) have attracted unprecedented attention for their impressive representation learning ability. However, the pretext task, Masked Image Modeling (MIM), reconstructs the missing local patches, lacking the global understanding of the image. This paper extends MAE to a fully supervised setting by adding a supervised classification branch, thereby enabling MAE to learn global features from golden labels effectively. The proposed Supervised MAE (SupMAE) only exploits a visible subset of image patches for classification, unlike the standard supervised pre-training where all image patches are used. Through experiments, we demonstrate that SupMAE is not only more training efficient but it also learns more robust and transferable features. Specifically, SupMAE achieves comparable performance with MAE using only 30% of compute when evaluated on ImageNet with the ViT-B/16 model. SupMAE's robustness on ImageNet variants and transfer learning performance outperforms MAE and standard supervised pre-training counterparts. Codes are available at https://github.com/enyac-group/supmae.
PDF Abstract


 ImageNet
ImageNet
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 Hateful Memes
Hateful Memes
 RESISC45
RESISC45
