TextFusion: Unveiling the Power of Textual Semantics for Controllable Image Fusion
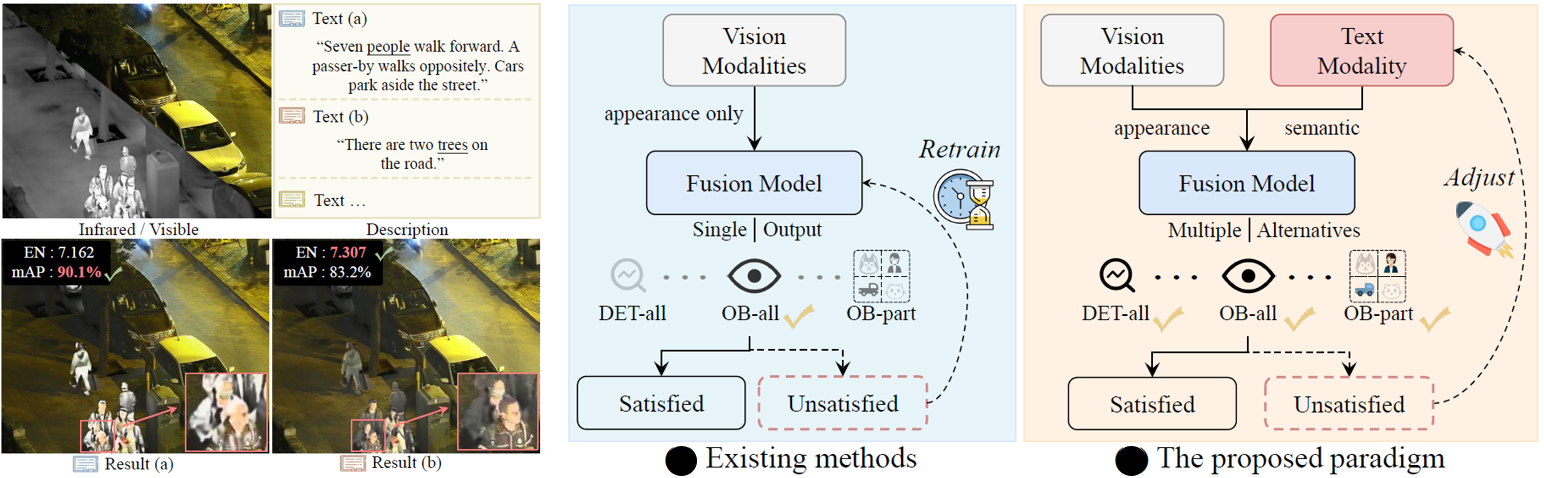
Advanced image fusion methods are devoted to generating the fusion results by aggregating the complementary information conveyed by the source images. However, the difference in the source-specific manifestation of the imaged scene content makes it difficult to design a robust and controllable fusion process. We argue that this issue can be alleviated with the help of higher-level semantics, conveyed by the text modality, which should enable us to generate fused images for different purposes, such as visualisation and downstream tasks, in a controllable way. This is achieved by exploiting a vision-and-language model to build a coarse-to-fine association mechanism between the text and image signals. With the guidance of the association maps, an affine fusion unit is embedded in the transformer network to fuse the text and vision modalities at the feature level. As another ingredient of this work, we propose the use of textual attention to adapt image quality assessment to the fusion task. To facilitate the implementation of the proposed text-guided fusion paradigm, and its adoption by the wider research community, we release a text-annotated image fusion dataset IVT. Extensive experiments demonstrate that our approach (TextFusion) consistently outperforms traditional appearance-based fusion methods. Our code and dataset will be publicly available at https://github.com/AWCXV/TextFusion.
PDF Abstract


 LLVIP
LLVIP
