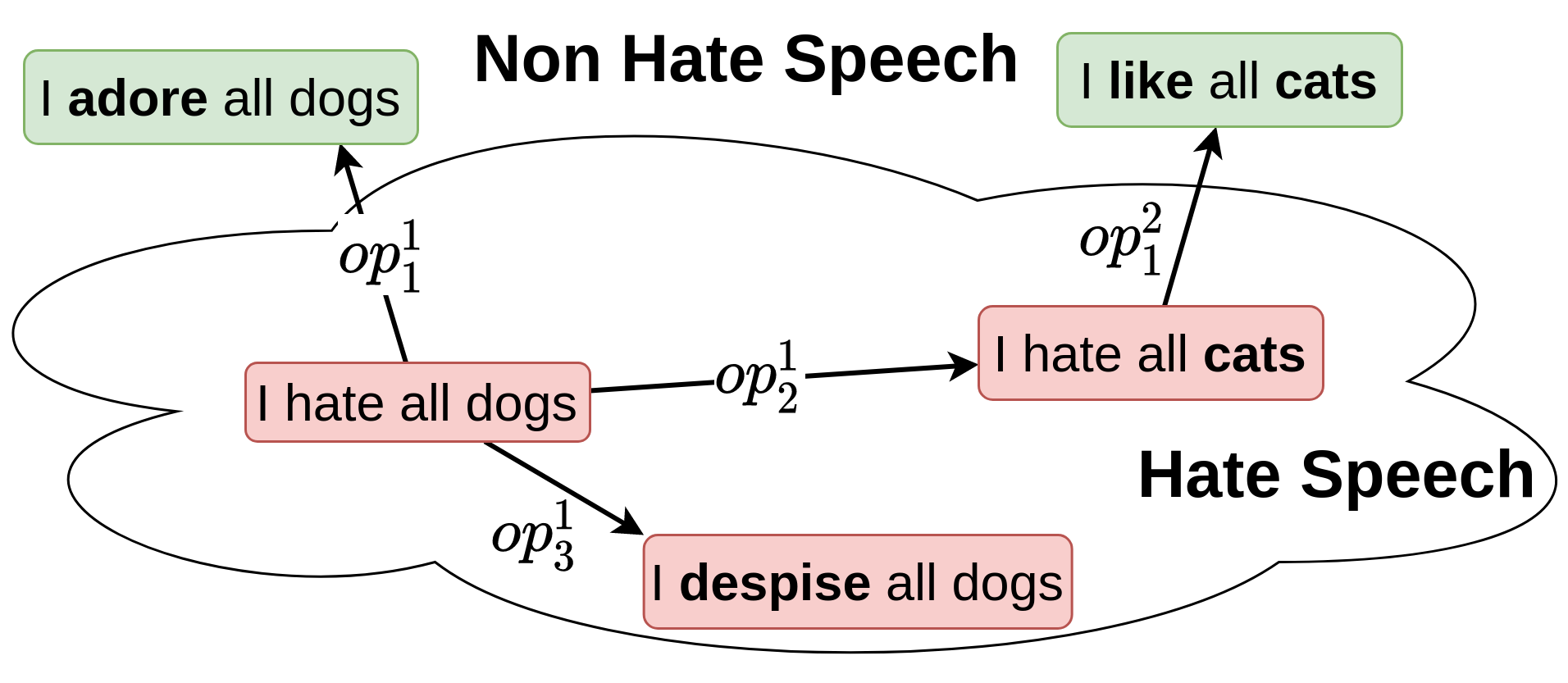
Textual Membership Queries
Human labeling of data can be very time-consuming and expensive, yet, in many cases it is critical for the success of the learning process. In order to minimize human labeling efforts, we propose a novel active learning solution that does not rely on existing sources of unlabeled data. It uses a small amount of labeled data as the core set for the synthesis of useful membership queries (MQs) - unlabeled instances generated by an algorithm for human labeling. Our solution uses modification operators, functions that modify instances to some extent. We apply the operators on a small set of instances (core set), creating a set of new membership queries. Using this framework, we look at the instance space as a search space and apply search algorithms in order to generate new examples highly relevant to the learner. We implement this framework in the textual domain and test it on several text classification tasks and show improved classifier performance as more MQs are labeled and incorporated into the training set. To the best of our knowledge, this is the first work on membership queries in the textual domain.
PDF Abstract


 SST
SST
