Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification
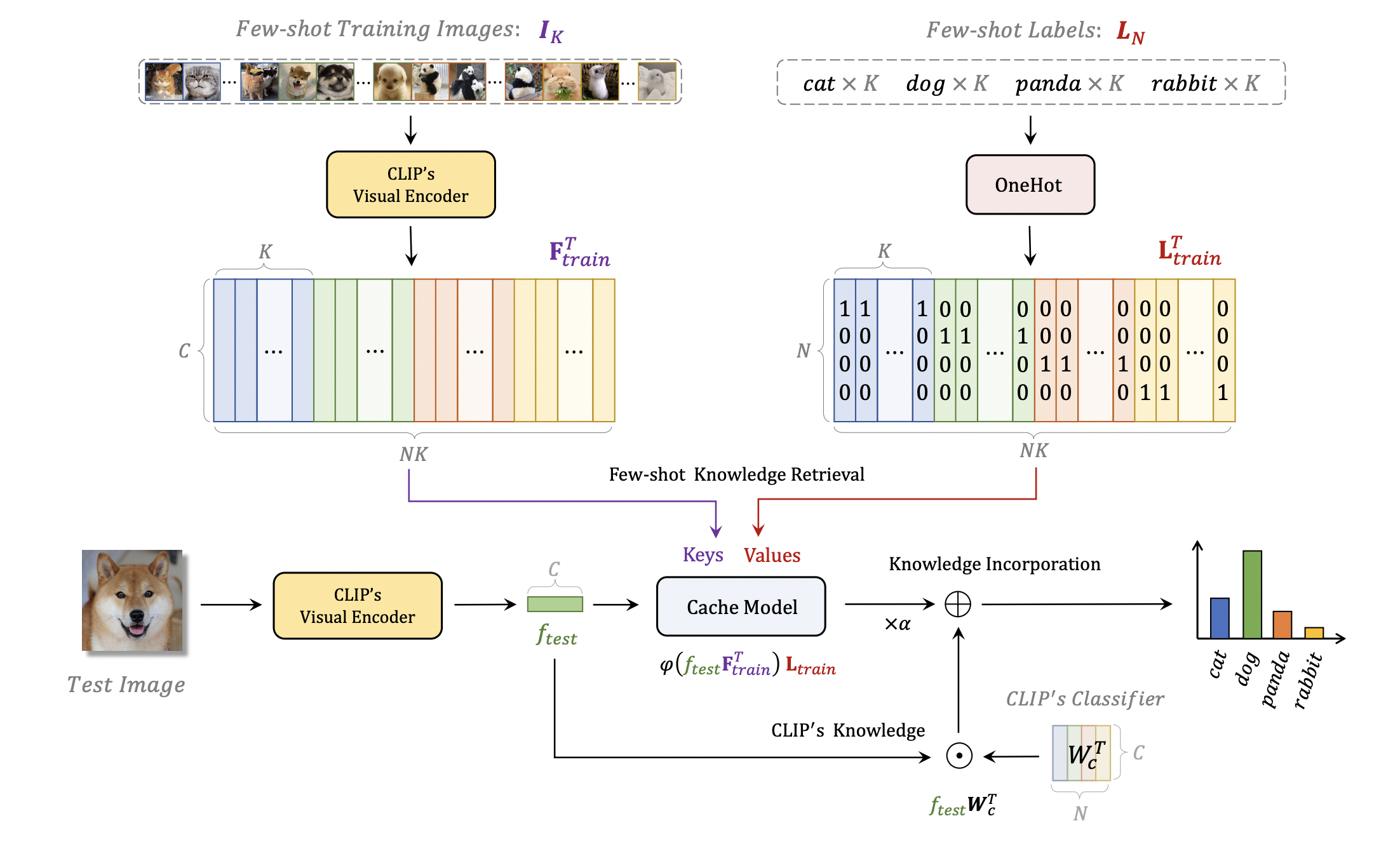
Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations using large-scale image-text pairs. It shows impressive performance on downstream tasks by zero-shot knowledge transfer. To further enhance CLIP's adaption capability, existing methods proposed to fine-tune additional learnable modules, which significantly improves the few-shot performance but introduces extra training time and computational resources. In this paper, we propose a training-free adaption method for CLIP to conduct few-shot classification, termed as Tip-Adapter, which not only inherits the training-free advantage of zero-shot CLIP but also performs comparably to those training-required approaches. Tip-Adapter constructs the adapter via a key-value cache model from the few-shot training set, and updates the prior knowledge encoded in CLIP by feature retrieval. On top of that, the performance of Tip-Adapter can be further boosted to be state-of-the-art on ImageNet by fine-tuning the cache model for 10$\times$ fewer epochs than existing methods, which is both effective and efficient. We conduct extensive experiments of few-shot classification on 11 datasets to demonstrate the superiority of our proposed methods. Code is released at https://github.com/gaopengcuhk/Tip-Adapter.
PDF Abstract


 Oxford 102 Flower
Oxford 102 Flower
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
