TMT: Tri-Modal Translation between Speech, Image, and Text by Processing Different Modalities as Different Languages
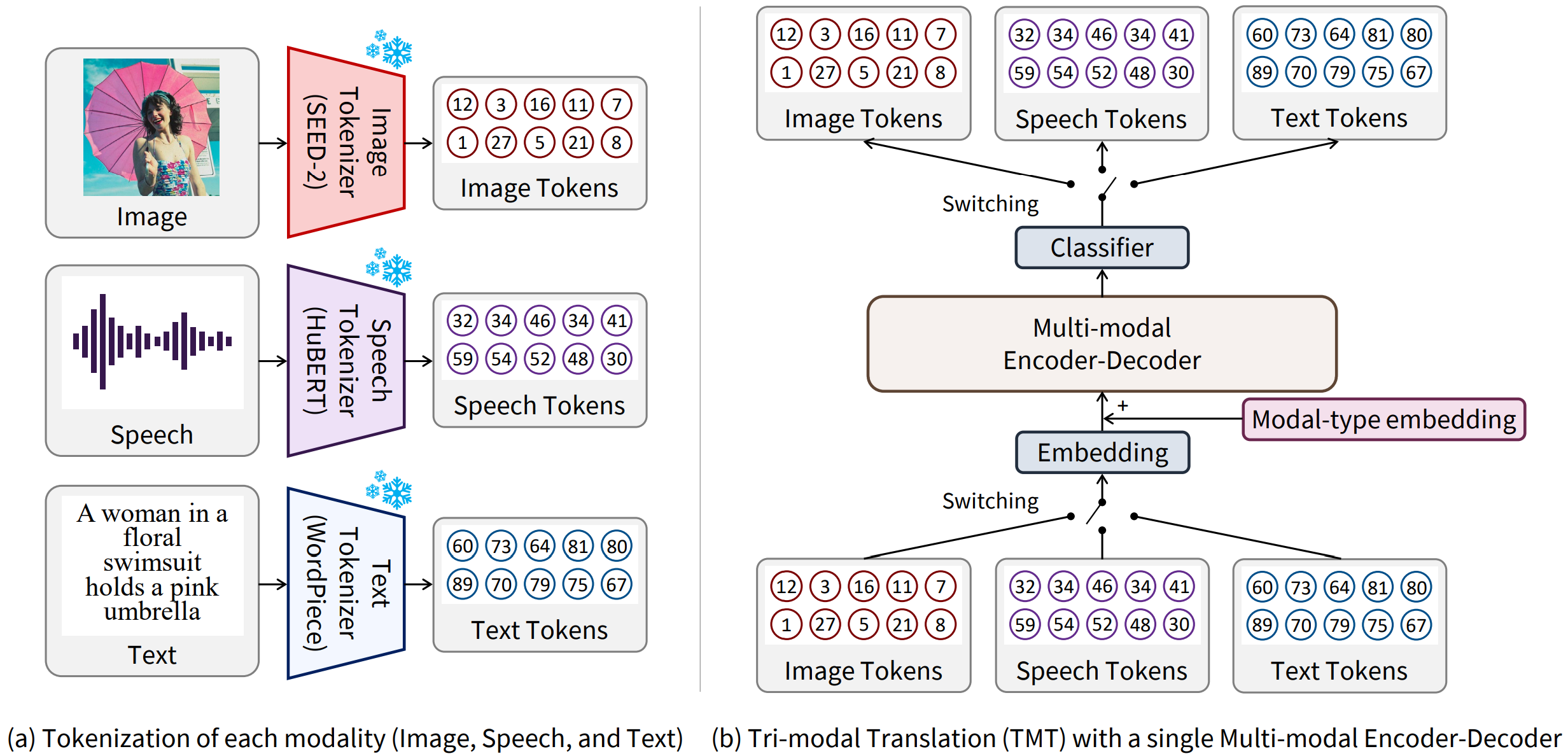
The capability to jointly process multi-modal information is becoming an essential task. However, the limited number of paired multi-modal data and the large computational requirements in multi-modal learning hinder the development. We propose a novel Tri-Modal Translation (TMT) model that translates between arbitrary modalities spanning speech, image, and text. We introduce a novel viewpoint, where we interpret different modalities as different languages, and treat multi-modal translation as a well-established machine translation problem. To this end, we tokenize speech and image data into discrete tokens, which provide a unified interface across modalities and significantly decrease the computational cost. In the proposed TMT, a multi-modal encoder-decoder conducts the core translation, whereas modality-specific processing is conducted only within the tokenization and detokenization stages. We evaluate the proposed TMT on all six modality translation tasks. TMT outperforms single model counterparts consistently, demonstrating that unifying tasks is beneficial not only for practicality but also for performance.
PDF Abstract


 MS COCO
MS COCO
 Conceptual Captions
Conceptual Captions
 CC12M
CC12M
