Towards Demystifying Representation Learning with Non-contrastive Self-supervision
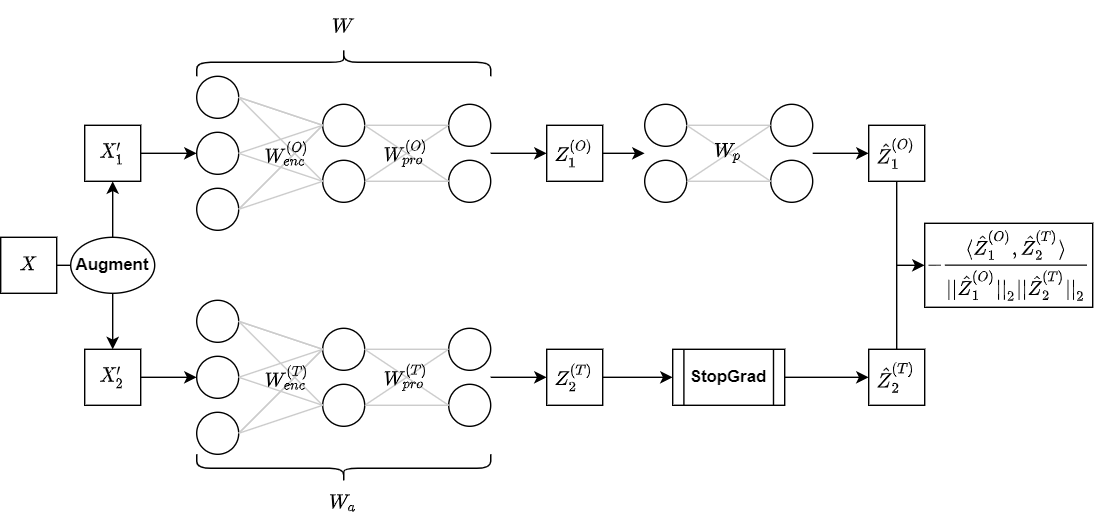
Non-contrastive methods of self-supervised learning (such as BYOL and SimSiam) learn representations by minimizing the distance between two views of the same image. These approaches have achieved remarkable performance in practice, but the theoretical understanding lags behind. Tian et al. 2021 explained why the representation does not collapse to zero, however, how the feature is learned still remains mysterious. In our work, we prove in a linear network, non-contrastive methods learn a desirable projection matrix and also reduce the sample complexity on downstream tasks. Our analysis suggests that weight decay acts as an implicit threshold that discards the features with high variance under data augmentations, and keeps the features with low variance. Inspired by our theory, we design a simpler and more computationally efficient algorithm DirectCopy by removing the eigen-decomposition step in the original DirectPred algorithm in Tian et al. 2021. Our experiments show that DirectCopy rivals or even outperforms DirectPred on STL-10, CIFAR-10, CIFAR-100, and ImageNet.
PDF Abstract



 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 STL-10
STL-10
