Towards Good Practices for Missing Modality Robust Action Recognition
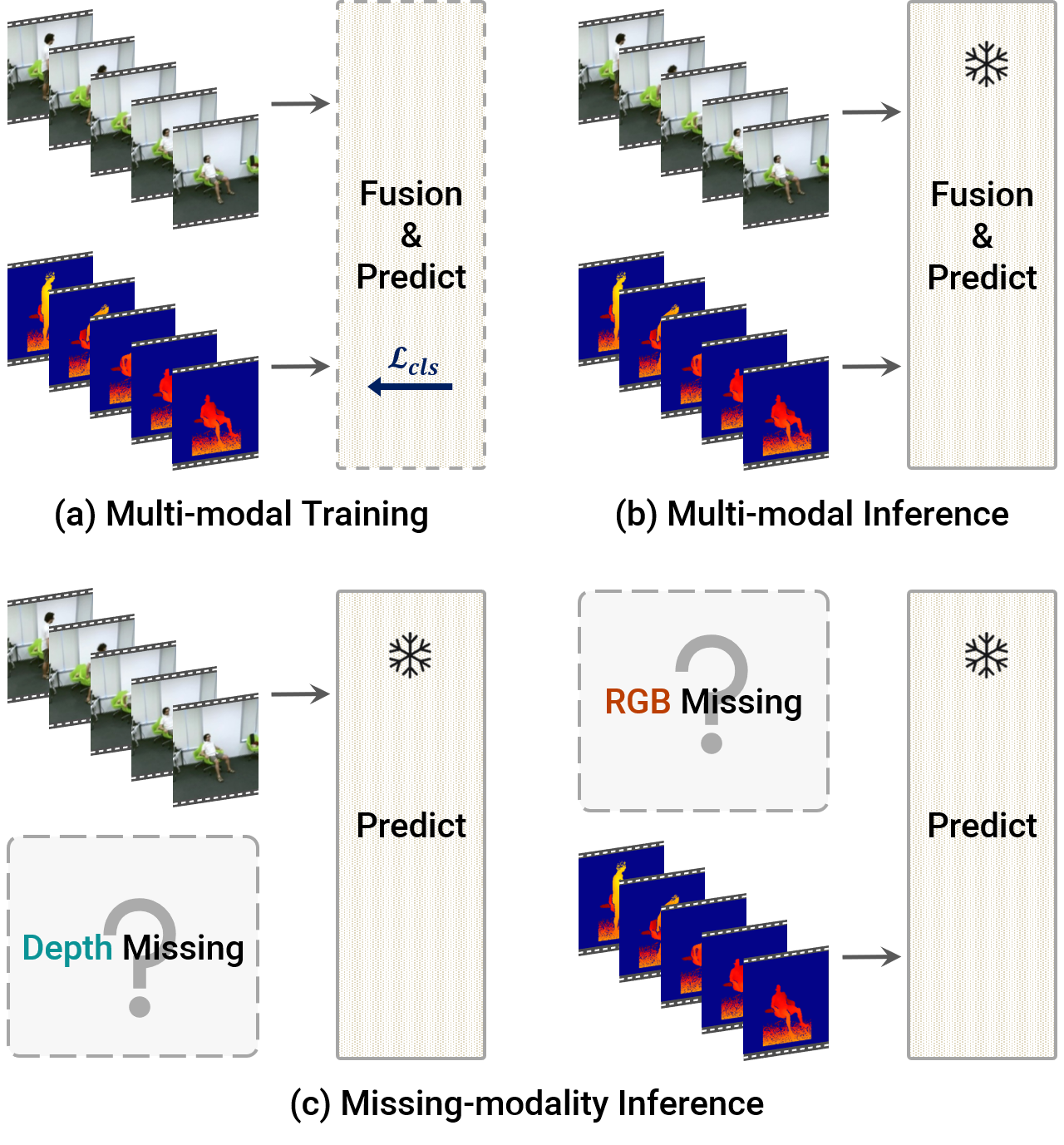
Standard multi-modal models assume the use of the same modalities in training and inference stages. However, in practice, the environment in which multi-modal models operate may not satisfy such assumption. As such, their performances degrade drastically if any modality is missing in the inference stage. We ask: how can we train a model that is robust to missing modalities? This paper seeks a set of good practices for multi-modal action recognition, with a particular interest in circumstances where some modalities are not available at an inference time. First, we study how to effectively regularize the model during training (e.g., data augmentation). Second, we investigate on fusion methods for robustness to missing modalities: we find that transformer-based fusion shows better robustness for missing modality than summation or concatenation. Third, we propose a simple modular network, ActionMAE, which learns missing modality predictive coding by randomly dropping modality features and tries to reconstruct them with the remaining modality features. Coupling these good practices, we build a model that is not only effective in multi-modal action recognition but also robust to modality missing. Our model achieves the state-of-the-arts on multiple benchmarks and maintains competitive performances even in missing modality scenarios. Codes are available at https://github.com/sangminwoo/ActionMAE.
PDF Abstract


 ImageNet
ImageNet
 NTU RGB+D
NTU RGB+D
