Towards Open-Ended Visual Recognition with Large Language Model
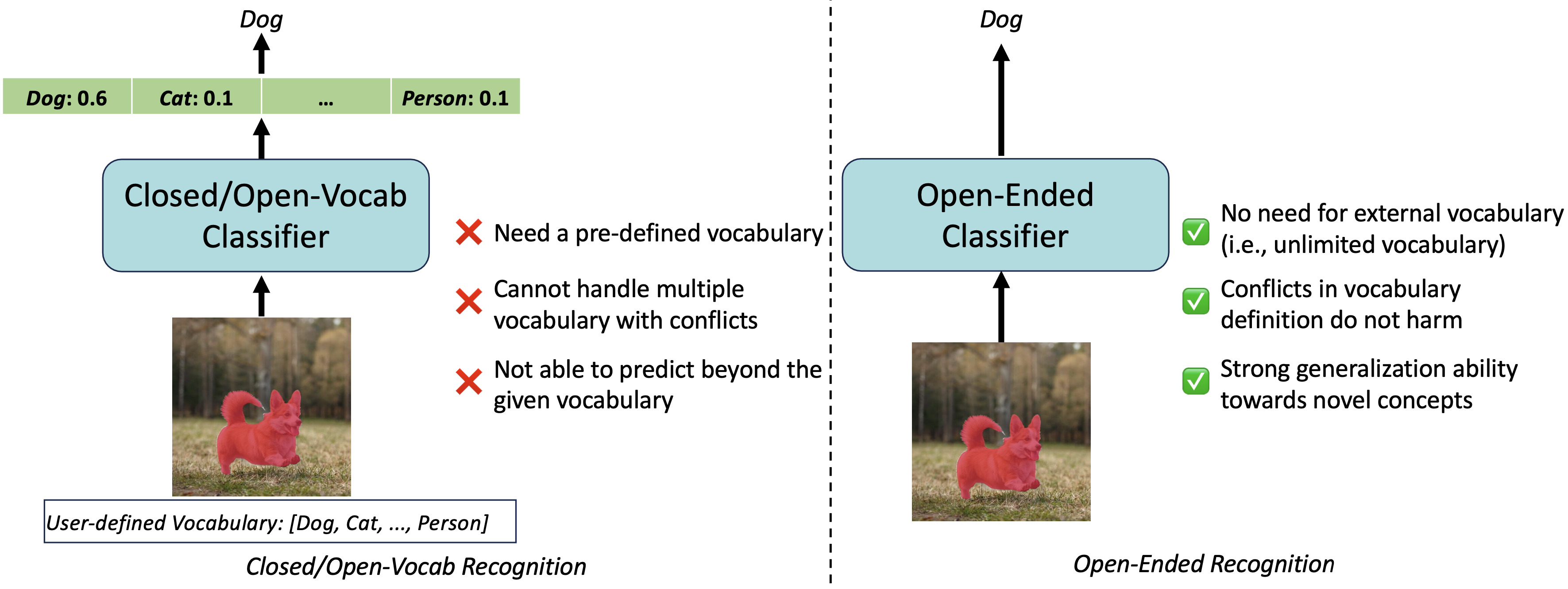
Localizing and recognizing objects in the open-ended physical world poses a long-standing challenge within the domain of machine perception. Recent methods have endeavored to address the issue by employing a class-agnostic mask (or box) proposal model, complemented by an open-vocabulary classifier (e.g., CLIP) using pre-extracted text embeddings. However, it is worth noting that these open-vocabulary recognition models still exhibit limitations in practical applications. On one hand, they rely on the provision of class names during testing, where the recognition performance heavily depends on this predefined set of semantic classes by users. On the other hand, when training with multiple datasets, human intervention is required to alleviate the label definition conflict between them. In this paper, we introduce the OmniScient Model (OSM), a novel Large Language Model (LLM) based mask classifier, as a straightforward and effective solution to the aforementioned challenges. Specifically, OSM predicts class labels in a generative manner, thus removing the supply of class names during both training and testing. It also enables cross-dataset training without any human interference, exhibiting robust generalization capabilities due to the world knowledge acquired from the LLM. By combining OSM with an off-the-shelf mask proposal model, we present promising results on various benchmarks, and demonstrate its effectiveness in handling novel concepts. Code/model are available at https://github.com/bytedance/OmniScient-Model.
PDF Abstract


 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 LVIS
LVIS
