Towards Robust Unsupervised Disentanglement of Sequential Data -- A Case Study Using Music Audio
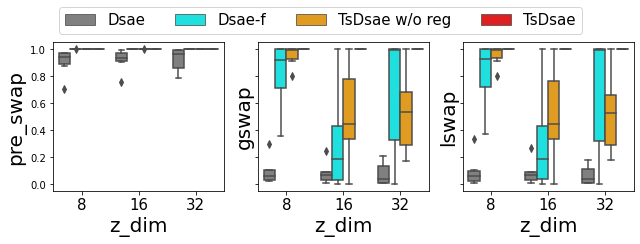
Disentangled sequential autoencoders (DSAEs) represent a class of probabilistic graphical models that describes an observed sequence with dynamic latent variables and a static latent variable. The former encode information at a frame rate identical to the observation, while the latter globally governs the entire sequence. This introduces an inductive bias and facilitates unsupervised disentanglement of the underlying local and global factors. In this paper, we show that the vanilla DSAE suffers from being sensitive to the choice of model architecture and capacity of the dynamic latent variables, and is prone to collapse the static latent variable. As a countermeasure, we propose TS-DSAE, a two-stage training framework that first learns sequence-level prior distributions, which are subsequently employed to regularise the model and facilitate auxiliary objectives to promote disentanglement. The proposed framework is fully unsupervised and robust against the global factor collapse problem across a wide range of model configurations. It also avoids typical solutions such as adversarial training which usually involves laborious parameter tuning, and domain-specific data augmentation. We conduct quantitative and qualitative evaluations to demonstrate its robustness in terms of disentanglement on both artificial and real-world music audio datasets.
PDF Abstract


 URMP
URMP
