Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
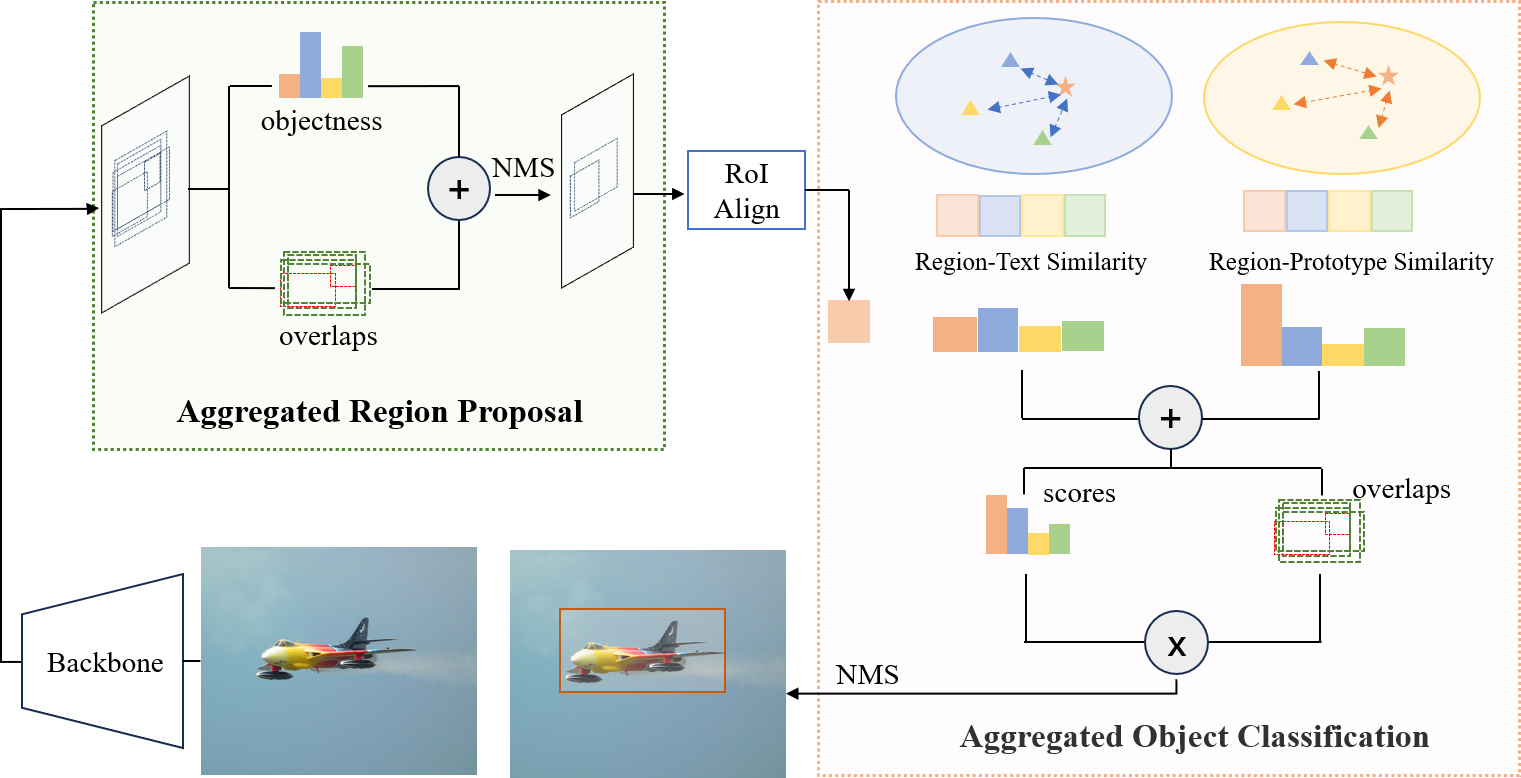
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
PDF Abstract
 Spaces
Spaces



 MS COCO
MS COCO
 LVIS
LVIS
