Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
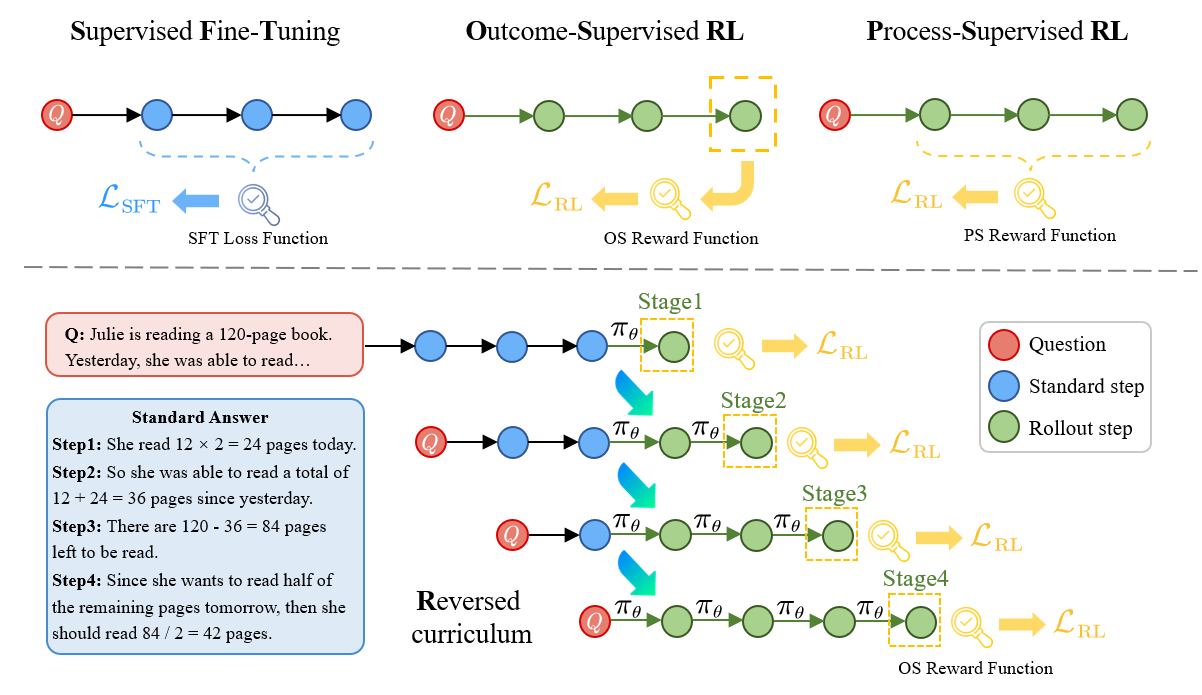
In this paper, we propose R$^3$: Learning Reasoning through Reverse Curriculum Reinforcement Learning (RL), a novel method that employs only outcome supervision to achieve the benefits of process supervision for large language models. The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision provides sparse rewards for final results without identifying error locations, whereas process supervision offers step-wise rewards but requires extensive manual annotation. R$^3$ overcomes these limitations by learning from correct demonstrations. Specifically, R$^3$ progressively slides the start state of reasoning from a demonstration's end to its beginning, facilitating easier model exploration at all stages. Thus, R$^3$ establishes a step-wise curriculum, allowing outcome supervision to offer step-level signals and precisely pinpoint errors. Using Llama2-7B, our method surpasses RL baseline on eight reasoning tasks by $4.1$ points on average. Notebaly, in program-based reasoning on GSM8K, it exceeds the baseline by $4.2$ points across three backbone models, and without any extra data, Codellama-7B + R$^3$ performs comparable to larger models or closed-source models.
PDF Abstract

 SNLI
SNLI
 GSM8K
GSM8K
 RACE
RACE
