Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents
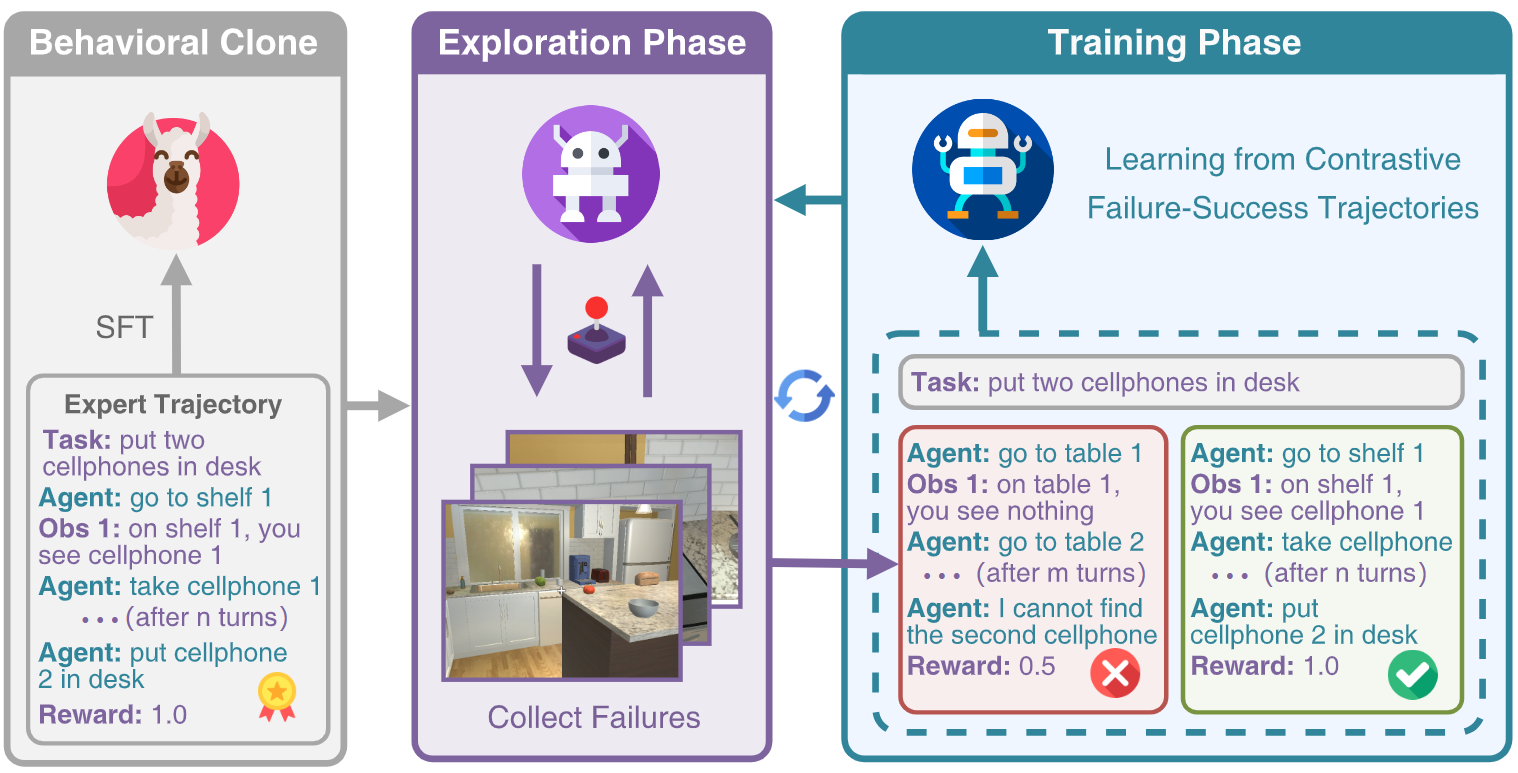
Large Language Models (LLMs) have become integral components in various autonomous agent systems. In this study, we present an exploration-based trajectory optimization approach, referred to as ETO. This learning method is designed to enhance the performance of open LLM agents. Contrary to previous studies that exclusively train on successful expert trajectories, our method allows agents to learn from their exploration failures. This leads to improved performance through an iterative optimization framework. During the exploration phase, the agent interacts with the environment while completing given tasks, gathering failure trajectories to create contrastive trajectory pairs. In the subsequent training phase, the agent utilizes these trajectory preference pairs to update its policy using contrastive learning methods like DPO. This iterative cycle of exploration and training fosters continued improvement in the agents. Our experiments on three complex tasks demonstrate that ETO consistently surpasses baseline performance by a large margin. Furthermore, an examination of task-solving efficiency and potential in scenarios lacking expert trajectory underscores the effectiveness of our approach.
PDF Abstract Spaces
Spaces


 ALFWorld
ALFWorld
