Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers
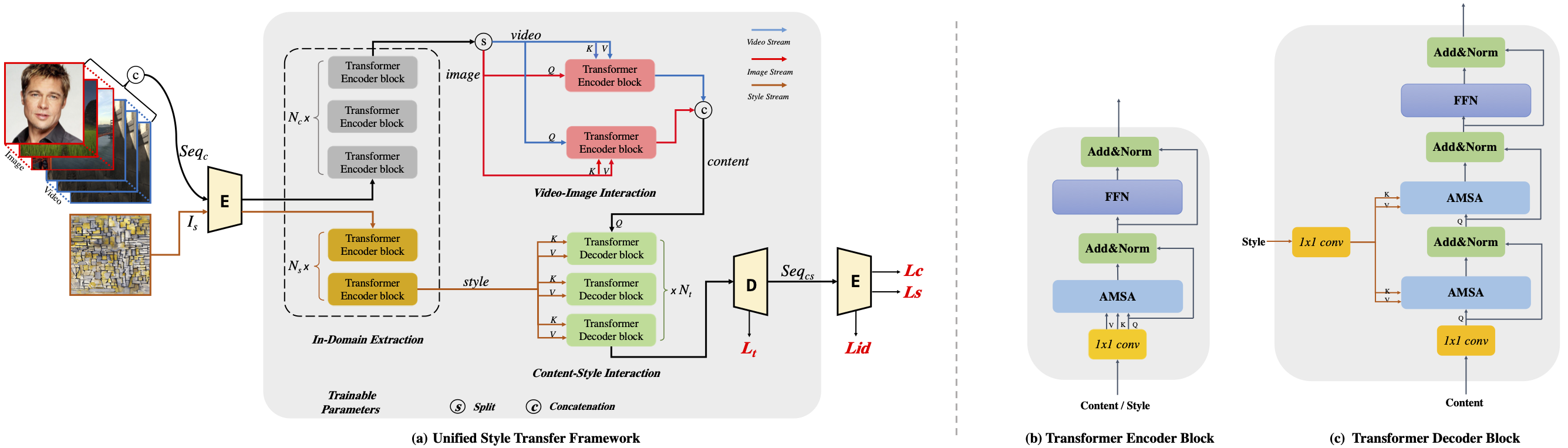
Current arbitrary style transfer models are limited to either image or video domains. In order to achieve satisfying image and video style transfers, two different models are inevitably required with separate training processes on image and video domains, respectively. In this paper, we show that this can be precluded by introducing UniST, a Unified Style Transfer framework for both images and videos. At the core of UniST is a domain interaction transformer (DIT), which first explores context information within the specific domain and then interacts contextualized domain information for joint learning. In particular, DIT enables exploration of temporal information from videos for the image style transfer task and meanwhile allows rich appearance texture from images for video style transfer, thus leading to mutual benefits. Considering heavy computation of traditional multi-head self-attention, we present a simple yet effective axial multi-head self-attention (AMSA) for DIT, which improves computational efficiency while maintains style transfer performance. To verify the effectiveness of UniST, we conduct extensive experiments on both image and video style transfer tasks and show that UniST performs favorably against state-of-the-art approaches on both tasks. Our code and results will be released.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 ImageNet
ImageNet
