Understanding the Role of Mixup in Knowledge Distillation: An Empirical Study
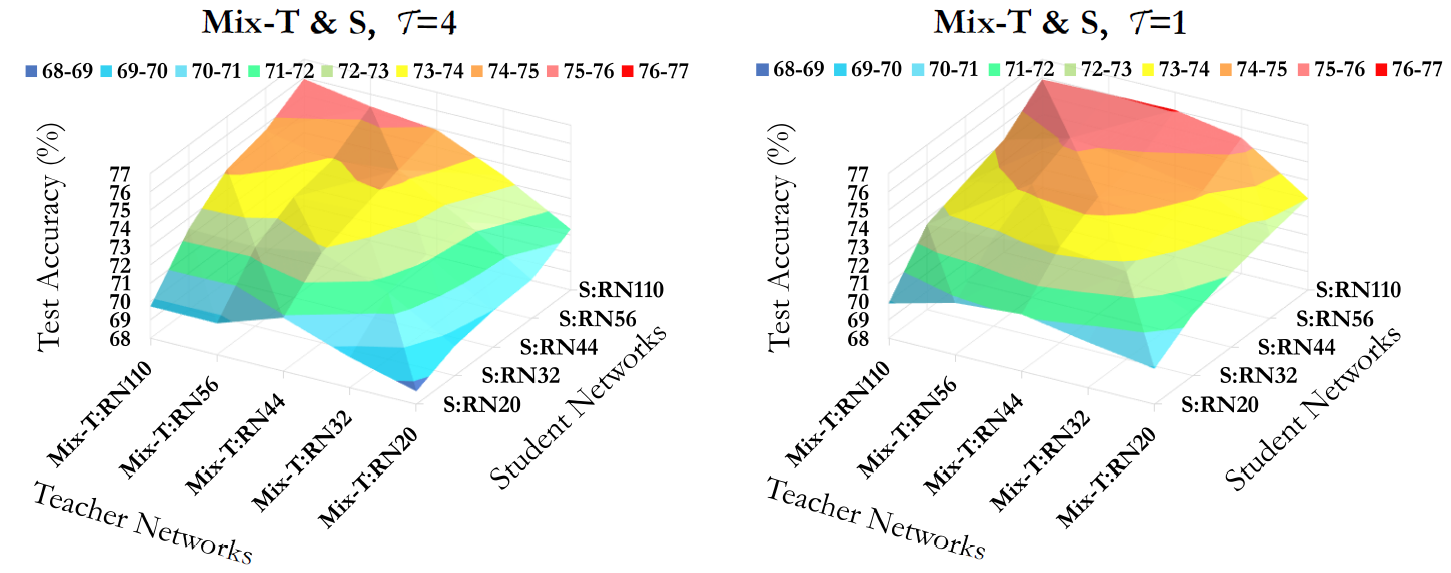
Mixup is a popular data augmentation technique based on creating new samples by linear interpolation between two given data samples, to improve both the generalization and robustness of the trained model. Knowledge distillation (KD), on the other hand, is widely used for model compression and transfer learning, which involves using a larger network's implicit knowledge to guide the learning of a smaller network. At first glance, these two techniques seem very different, however, we found that "smoothness" is the connecting link between the two and is also a crucial attribute in understanding KD's interplay with mixup. Although many mixup variants and distillation methods have been proposed, much remains to be understood regarding the role of a mixup in knowledge distillation. In this paper, we present a detailed empirical study on various important dimensions of compatibility between mixup and knowledge distillation. We also scrutinize the behavior of the networks trained with a mixup in the light of knowledge distillation through extensive analysis, visualizations, and comprehensive experiments on image classification. Finally, based on our findings, we suggest improved strategies to guide the student network to enhance its effectiveness. Additionally, the findings of this study provide insightful suggestions to researchers and practitioners that commonly use techniques from KD. Our code is available at https://github.com/hchoi71/MIX-KD.
PDF Abstract




 ImageNet
ImageNet
