Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning
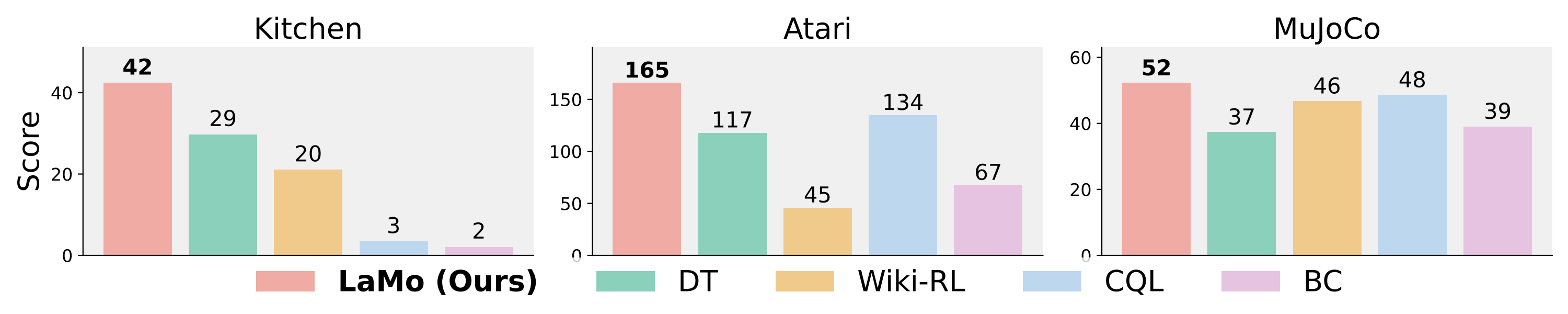
Offline reinforcement learning (RL) aims to find a near-optimal policy using pre-collected datasets. In real-world scenarios, data collection could be costly and risky; therefore, offline RL becomes particularly challenging when the in-domain data is limited. Given recent advances in Large Language Models (LLMs) and their few-shot learning prowess, this paper introduces $\textbf{La}$nguage Models for $\textbf{Mo}$tion Control ($\textbf{LaMo}$), a general framework based on Decision Transformers to effectively use pre-trained Language Models (LMs) for offline RL. Our framework highlights four crucial components: (1) Initializing Decision Transformers with sequentially pre-trained LMs, (2) employing the LoRA fine-tuning method, in contrast to full-weight fine-tuning, to combine the pre-trained knowledge from LMs and in-domain knowledge effectively, (3) using the non-linear MLP transformation instead of linear projections, to generate embeddings, and (4) integrating an auxiliary language prediction loss during fine-tuning to stabilize the LMs and retain their original abilities on languages. Empirical results indicate $\textbf{LaMo}$ achieves state-of-the-art performance in sparse-reward tasks and closes the gap between value-based offline RL methods and decision transformers in dense-reward tasks. In particular, our method demonstrates superior performance in scenarios with limited data samples.
PDF Abstract

 MuJoCo
MuJoCo
 D4RL
D4RL
