Unsupervised Attention-guided Image-to-Image Translation
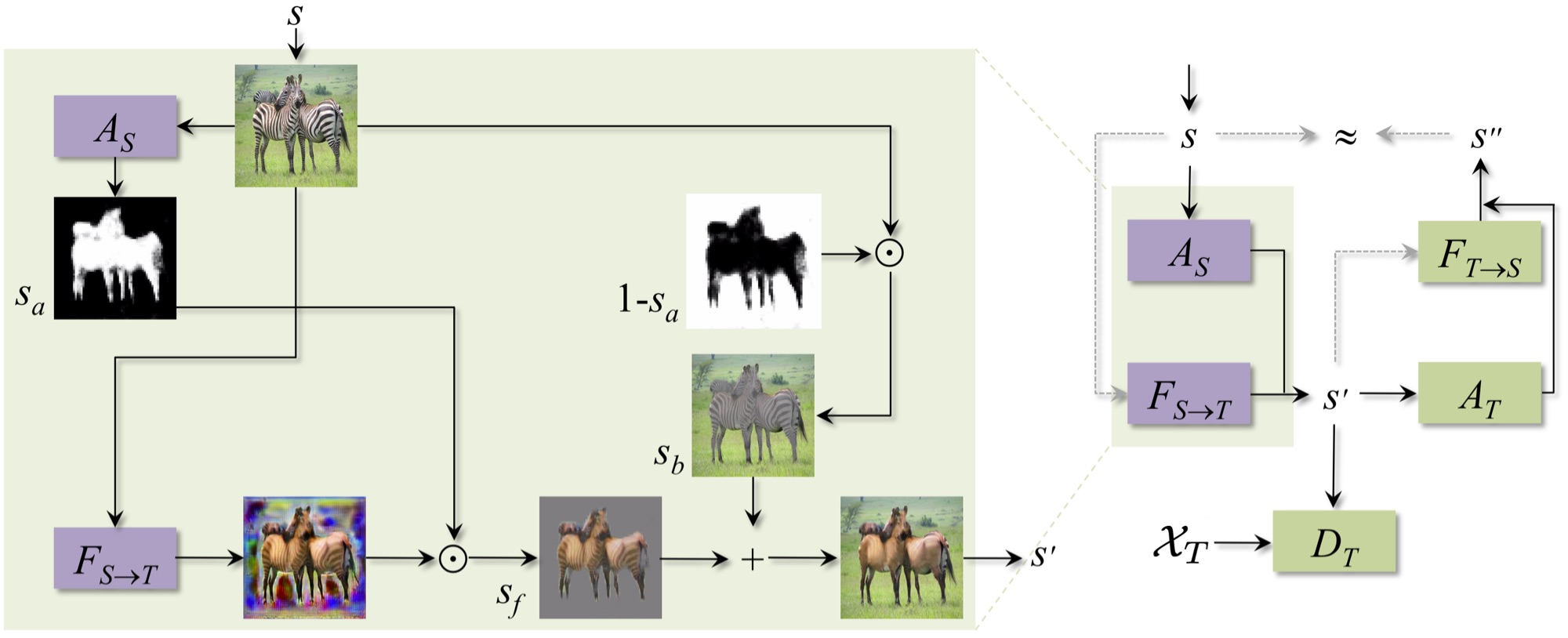
Current unsupervised image-to-image translation techniques struggle to focus their attention on individual objects without altering the background or the way multiple objects interact within a scene. Motivated by the important role of attention in human perception, we tackle this limitation by introducing unsupervised attention mechanisms which are jointly adversarially trained with the generators and discriminators. We empirically demonstrate that our approach is able to attend to relevant regions in the image without requiring any additional supervision, and that by doing so it achieves more realistic mappings compared to recent approaches.
PDF Abstract



Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
