Domain Adaptive Knowledge Distillation for Driving Scene Semantic Segmentation
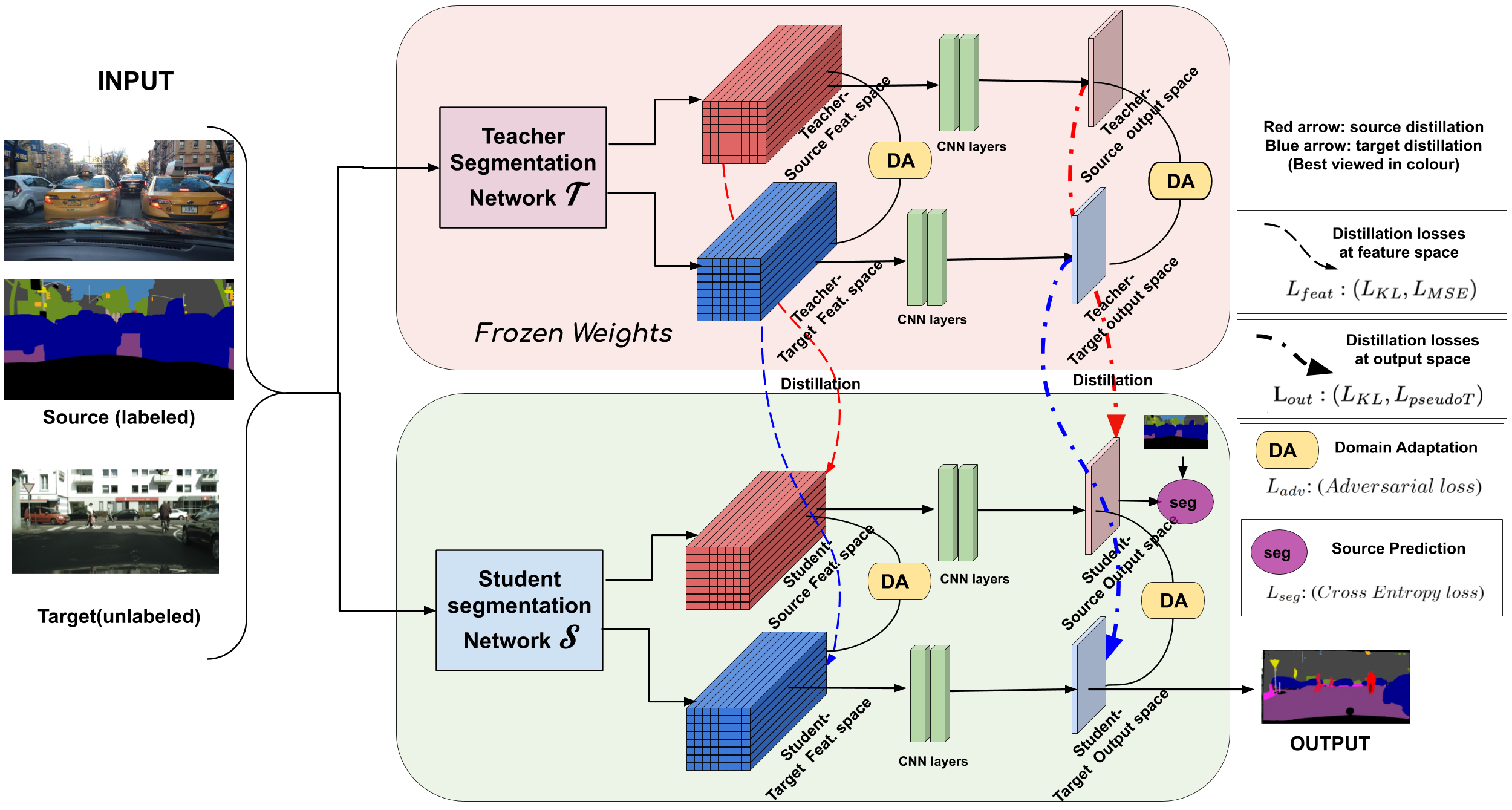
Practical autonomous driving systems face two crucial challenges: memory constraints and domain gap issues. In this paper, we present a novel approach to learn domain adaptive knowledge in models with limited memory, thus bestowing the model with the ability to deal with these issues in a comprehensive manner. We term this as "Domain Adaptive Knowledge Distillation" and address the same in the context of unsupervised domain-adaptive semantic segmentation by proposing a multi-level distillation strategy to effectively distil knowledge at different levels. Further, we introduce a novel cross entropy loss that leverages pseudo labels from the teacher. These pseudo teacher labels play a multifaceted role towards: (i) knowledge distillation from the teacher network to the student network & (ii) serving as a proxy for the ground truth for target domain images, where the problem is completely unsupervised. We introduce four paradigms for distilling domain adaptive knowledge and carry out extensive experiments and ablation studies on real-to-real as well as synthetic-to-real scenarios. Our experiments demonstrate the profound success of our proposed method.
PDF Abstract



 Cityscapes
Cityscapes
 GTA5
GTA5
