Diversity Helps: Unsupervised Few-shot Learning via Distribution Shift-based Data Augmentation
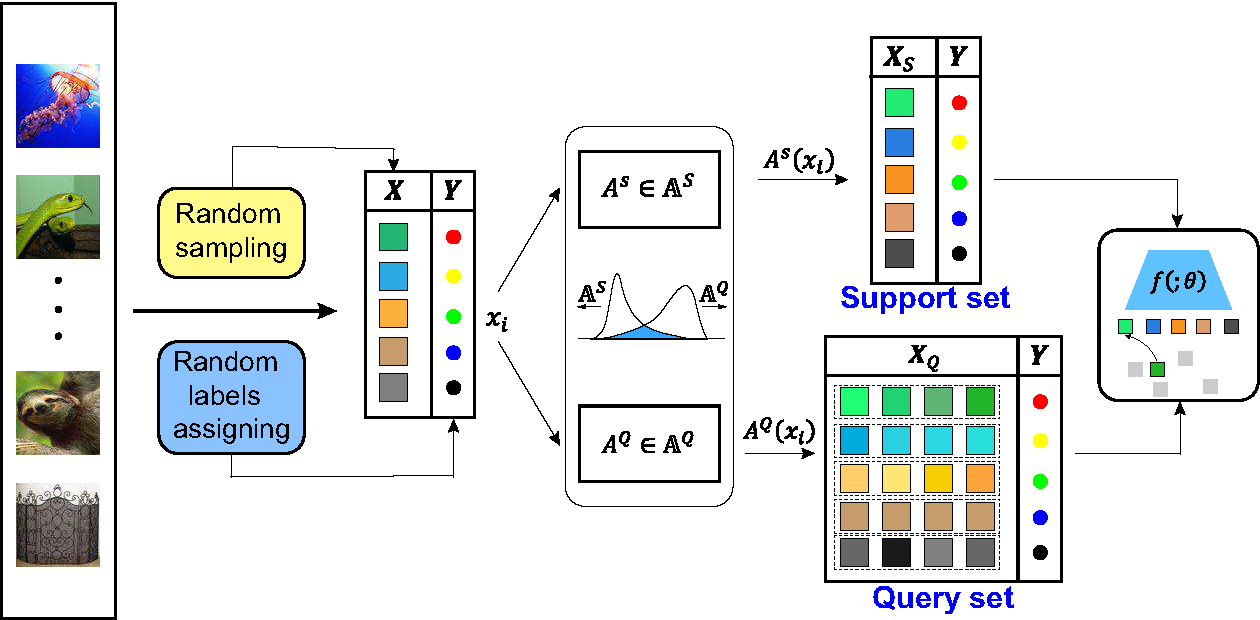
Few-shot learning aims to learn a new concept when only a few training examples are available, which has been extensively explored in recent years. However, most of the current works heavily rely on a large-scale labeled auxiliary set to train their models in an episodic-training paradigm. Such a kind of supervised setting basically limits the widespread use of few-shot learning algorithms. Instead, in this paper, we develop a novel framework called Unsupervised Few-shot Learning via Distribution Shift-based Data Augmentation (ULDA), which pays attention to the distribution diversity inside each constructed pretext few-shot task when using data augmentation. Importantly, we highlight the value and importance of the distribution diversity in the augmentation-based pretext few-shot tasks, which can effectively alleviate the overfitting problem and make the few-shot model learn more robust feature representations. In ULDA, we systemically investigate the effects of different augmentation techniques and propose to strengthen the distribution diversity (or difference) between the query set and support set in each few-shot task, by augmenting these two sets diversely (i.e., distribution shifting). In this way, even incorporated with simple augmentation techniques (e.g., random crop, color jittering, or rotation), our ULDA can produce a significant improvement. In the experiments, few-shot models learned by ULDA can achieve superior generalization performance and obtain state-of-the-art results in a variety of established few-shot learning tasks on Omniglot and miniImageNet. The source code is available in https://github.com/WonderSeven/ULDA.
PDF Abstract


 tieredImageNet
tieredImageNet

