Use What You Have: Video Retrieval Using Representations From Collaborative Experts
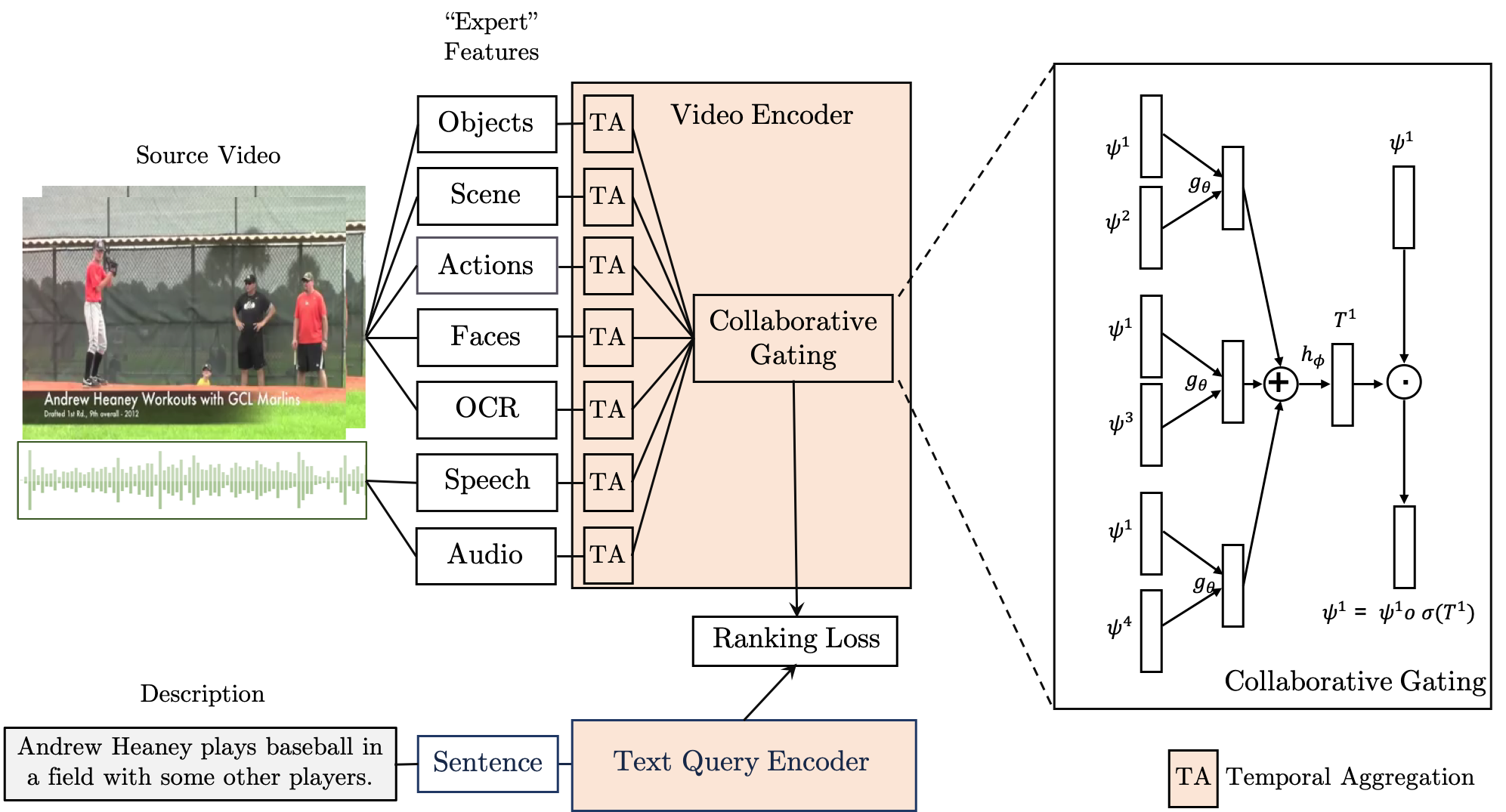
The rapid growth of video on the internet has made searching for video content using natural language queries a significant challenge. Human-generated queries for video datasets `in the wild' vary a lot in terms of degree of specificity, with some queries describing specific details such as the names of famous identities, content from speech, or text available on the screen. Our goal is to condense the multi-modal, extremely high dimensional information from videos into a single, compact video representation for the task of video retrieval using free-form text queries, where the degree of specificity is open-ended. For this we exploit existing knowledge in the form of pre-trained semantic embeddings which include 'general' features such as motion, appearance, and scene features from visual content. We also explore the use of more 'specific' cues from ASR and OCR which are intermittently available for videos and find that these signals remain challenging to use effectively for retrieval. We propose a collaborative experts model to aggregate information from these different pre-trained experts and assess our approach empirically on five retrieval benchmarks: MSR-VTT, LSMDC, MSVD, DiDeMo, and ActivityNet. Code and data can be found at www.robots.ox.ac.uk/~vgg/research/collaborative-experts/. This paper contains a correction to results reported in the previous version.
PDF Abstract

 ImageNet
ImageNet
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 DiDeMo
DiDeMo
 LSMDC
LSMDC

