VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
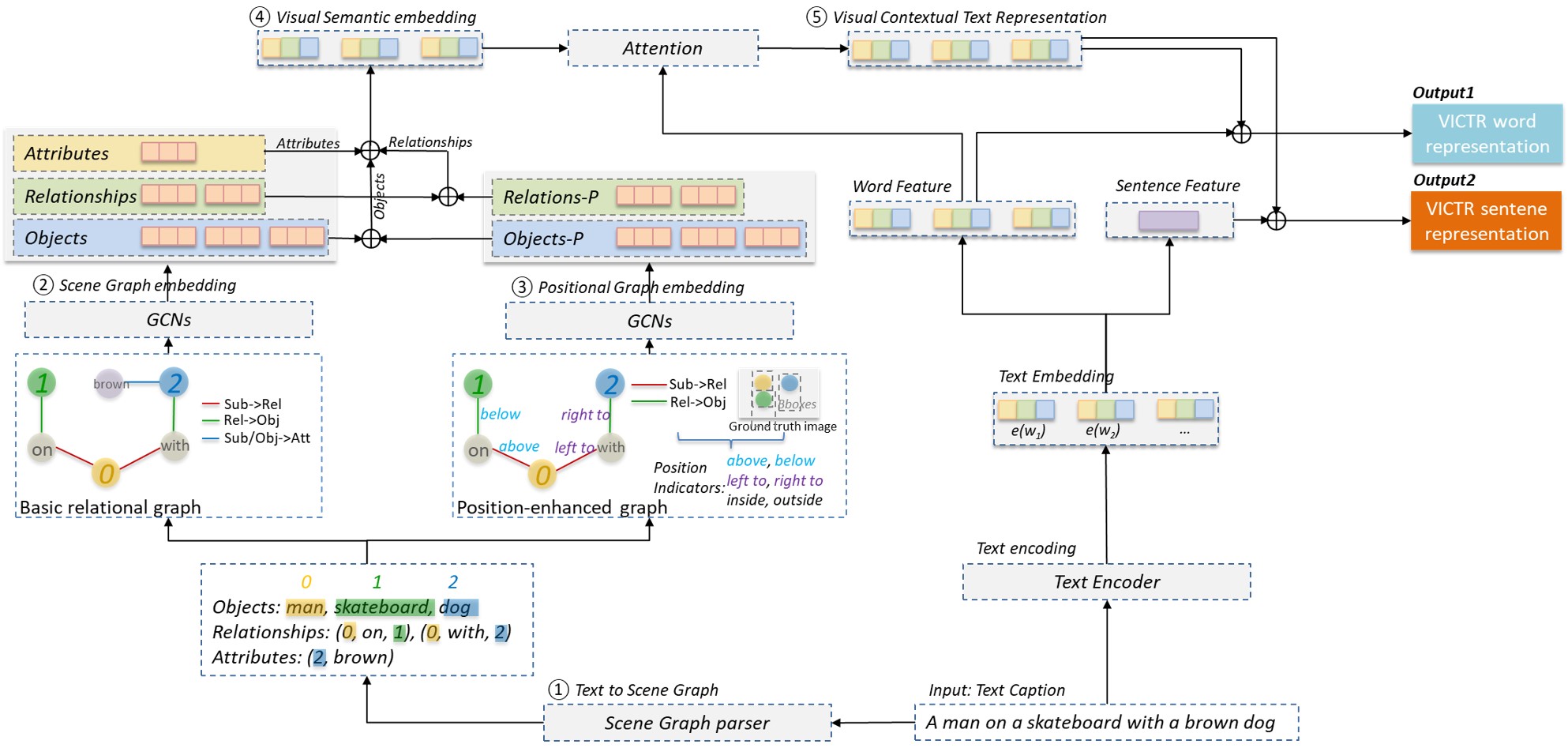
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
PDF Abstract


Datasets
 MS COCO
MS COCO
Results from the Paper
 Ranked #24 on
Text-to-Image Generation
on MS COCO
(Inception score metric)
Ranked #24 on
Text-to-Image Generation
on MS COCO
(Inception score metric)
