Video Diffusion Models with Local-Global Context Guidance
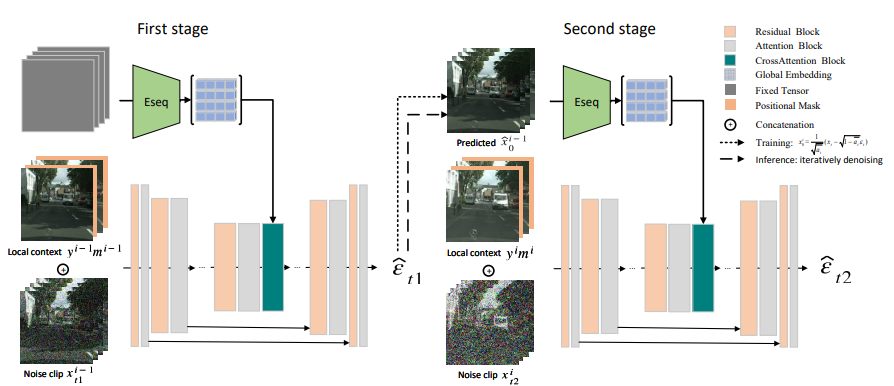
Diffusion models have emerged as a powerful paradigm in video synthesis tasks including prediction, generation, and interpolation. Due to the limitation of the computational budget, existing methods usually implement conditional diffusion models with an autoregressive inference pipeline, in which the future fragment is predicted based on the distribution of adjacent past frames. However, only the conditions from a few previous frames can't capture the global temporal coherence, leading to inconsistent or even outrageous results in long-term video prediction. In this paper, we propose a Local-Global Context guided Video Diffusion model (LGC-VD) to capture multi-perception conditions for producing high-quality videos in both conditional/unconditional settings. In LGC-VD, the UNet is implemented with stacked residual blocks with self-attention units, avoiding the undesirable computational cost in 3D Conv. We construct a local-global context guidance strategy to capture the multi-perceptual embedding of the past fragment to boost the consistency of future prediction. Furthermore, we propose a two-stage training strategy to alleviate the effect of noisy frames for more stable predictions. Our experiments demonstrate that the proposed method achieves favorable performance on video prediction, interpolation, and unconditional video generation. We release code at https://github.com/exisas/LGC-VD.
PDF Abstract




 Cityscapes
Cityscapes
